Release 2 (9.2)
Part Number A96621-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i XML Developer's Kits Guide - XDK Release 2 (9.2) Part Number A96621-01 |
|
This chapter contains the following sections:
Oracle provides a set of XML parsers for Java, C, C++, and PL/SQL. Each of these parsers is a standalone XML component that parses an XML document (or a standalone DTD or XML Schema) so that it can be processed by an application. This chapter discusses the parser for Java only. The other language versions are discussed in later chapters.
Library and command-line versions are provided supporting the following standards and features:
These APIs permit applications to access and manipulate an XML document as a tree structure in memory. This interface is used by such applications as editors.
Additional features include:
The parsers are available on all Oracle platforms.
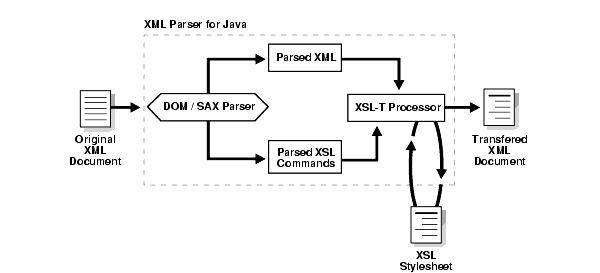
Figure 4-1 shows an XML document inputting XML Parser for Java. The DOM or SAX parser interface parses the XML document. The parsed XML is then transferred to the application for further processing.
If a stylesheet is used, the DOM or SAX interface also parses and outputs the XSL commands. These are sent together with the parsed XML to the XSLT Processor where the selected stylesheet is applied and the transformed (new) XML document is then output.
DOM and SAX APIs are explained in "DOM and SAX APIs".
The classes and methods used to parse an XML document are illustrated in the following diagrams:
The classes and methods used by the XSLT Processor to apply stylesheets are illustrated in the following diagram:
The V2 versions of the XML Parsers include an integrated XSL Transformation (XSLT) Processor for transforming XML data using XSL stylesheets. Using the XSLT processor, you can transform XML documents from XML to XML, XML to HTML, or to virtually any other text-based format. See Figure 4-1.
| See Also:
Chapter 5, "XSLT Processor for Java" for complete details. |
The Java XML parser also supports XML Namespaces. Namespaces are a mechanism to resolve or avoid name collisions between element types (tags) or attributes in XML documents.
This mechanism provides "universal" namespace element types and attribute names whose scope extends beyond this manual.
Such tags are qualified by uniform resource identifiers (URIs), such as:
<oracle:EMP xmlns:oracle="http://www.oracle.com/xml"/>
For example, namespaces can be used to identify an Oracle <EMP> data element as distinct from another company's definition of an <EMP> data element.
This enables an application to more easily identify elements and attributes it is designed to process. The Java parser supports namespaces by being able to recognize and parse universal element types and attribute names, as well as unqualified "local" element types and attribute names.
The Java parser can parse XML in validating or non-validating modes.
Validation involves checking whether or not the attribute names and element tags are legal, whether nested elements belong where they are, and so on.
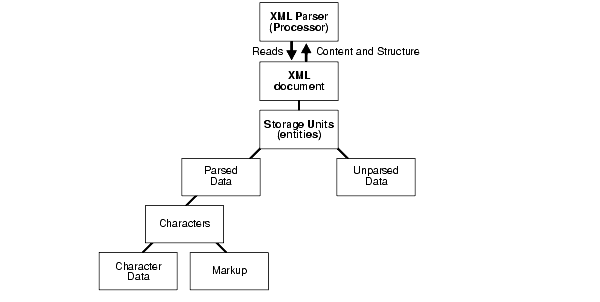
XML documents are made up of storage units called entities, which contain either parsed or unparsed data. Parsed data is made up of characters, some of which form character data, and some of which form markup.
Markup encodes a description of the document's storage layout and logical structure. XML provides a mechanism to impose constraints on the storage layout and logical structure.
A software module called an XML processor is used to read XML documents and provide access to their content and structure. It is assumed that an XML processor is doing its work on behalf of another module, called the application.
This parsing process is illustrated in Figure 4-2.
XML APIs generally fall into the following two categories:
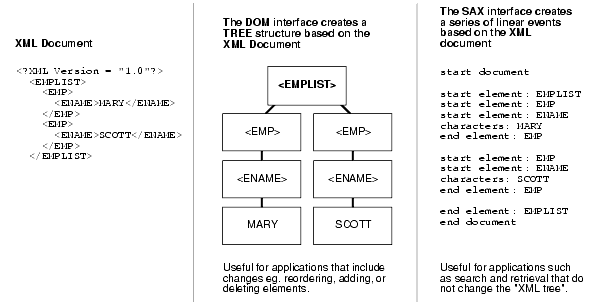
See Figure 4-3. Consider the following simple XML document:
<?xml version="1.0"?> <EMPLIST> <EMP> <ENAME>MARY</ENAME> </EMP> <EMP> <ENAME>SCOTT</ENAME> </EMP> </EMPLIST>
A tree-based API (such as DOM) builds an in-memory tree representation of the XML document. It provides classes and methods for an application to navigate and process the tree.
In general, the DOM interface is most useful for structural manipulations of the XML tree, such as reordering elements, adding or deleting elements and attributes, renaming elements, and so on. For example, for the XML document preceding, the DOM creates an in-memory tree structure as shown inFigure 4-3.
An event-based API (such as SAX) uses calls to report parsing events to the application. The application deals with these events through customized event handlers. Events include the start and end of elements and characters.
Unlike tree-based APIs, event-based APIs usually do not build in-memory tree representations of the XML documents. Therefore, in general, SAX is useful for applications that do not need to manipulate the XML tree, such as search operations, among others.
The preceding XML document becomes a series of linear events as shown in Figure 4-3.
Here are some guidelines for using the DOM and SAX APIs:
Use the SAX API when your data is mostly streaming data.
This release supports binary compression of XML documents. The compression is based on tokenizing the XML tags. The assumption is that any XML document has a repeated number of tags and so tokenizing these tags will give considerable amount of compression. Therefore the compression achieved depends on the type of input document; the larger the tags and the lesser the text content, then the better the compression.
The goal of compression is to reduce the size of the XML document without loosing the structural and hierarchical information of the DOM tree. The compressed stream contains all the "useful" information to create the DOM tree back from the binary format. The compressed stream can also be generated from the SAX events. The binary stream generated from DOM and SAX are compatible. The compressed stream generated from SAX could be used to generate the DOM tree and vice versa.
Sample programs to illustrate the compression feature is included in demos.
Oracle XML Parser can also compress XML documents. Using the compression feature, an in-memory DOM tree or the SAX events generated from an XML document can be compressed to generate a binary compressed output.
The compressed stream generated from DOM and SAX are compatible, that is, the compressed stream generated from SAX could be used to generate the DOM tree and vice versa. The compression is based on tokenizing the XML tags. This is based on the assumption that XML files typically have repeated tags and tokenizing the tags compresses the data. The compression depends on the type of input XML document: the larger the number of tags, the less the text content, and the better the compression.
As with XML documents in general, you can store the compressed XML data output as a BLOB (Binary Large Object) in the database.
An XML document is compressed into a binary stream by means of the serialization of an in-memory DOM tree. When a large XML document is parsed and a DOM tree is created in memory corresponding to it, it may be difficult to satisfy memory requirements and this could affect performance. The XML document is compressed into a byte stream and stored in an in-memory DOM tree. This can be expanded at a later time into a DOM tree without performing validation on the XML data stored in the compressed stream.
The compressed stream can be treated as a serialized stream, but note that the information in the stream is more controlled and managed, compared to the compression implemented by Java's default serialization.
In this release, there are two kinds of XML compressed streams:
The compressed stream is generated using SAX events and that generated using DOM serialization are compatible. You can use the compressed stream generated by SAX events to create a DOM tree and vice versa. The compression algorithm used is based on tokenizing the XML tag's. The assumption is that any XML file has repeated number of tags and therefore tokenizing the tags will give considerable compression.
The directory demo/java/parser contains some sample XML applications to show how to use the Oracle XML parser.
The following are the sample Java files in the sub-directories:
The Tokenizer application implements XMLToken interface, which must be registered using the setTokenHandler() method. A request for the XML tokens is registered using the setToken() method. During tokenizing, the parser doesn't validate the document and does not include or read internal/external utilities.
To run these sample programs:
make to generate .class files.xmlparserv2.jar and the current directory to the CLASSPATH.java classname sample_xml_file
java XSLSample sample_xsl_file sample_xml_file
java Tokenizer sample_xml_file token_string
java DOMCompression sample.dat
The compressed output is generated in a file called "xml.ser"
java DeCompression xml.ser
java SAXCompression sample.dat
java SAXDeCompression xml.ser
java JAXPExamples
the .xml and .xsl are given inside JAXPExamples.java
A few .xml and files are provided as test cases in directory common.
The XSL stylesheet iden.xsl can be used to achieve an identity transformation of the XML files in a common directory.
<?xml version = "1.0"?> <!DOCTYPE course [ <!ELEMENT course (Name, Dept, Instructor, Student)> <!ELEMENT Name (#PCDATA)> <!ELEMENT Dept (#PCDATA)> <!ELEMENT Instructor (Name)> <!ELEMENT Student (Name*)> ]> <course> <Name>Calculus</Name> <Dept>Math</Dept> <Instructor> <Name>Jim Green</Name> </Instructor> <Student> <Name>Jack</Name> <Name>Mary</Name> <Name>Paul</Name> </Student> </course>
<?xml version="1.0"?> <!DOCTYPE employee [ <!ELEMENT employee (Name, Dept, Title)> <!ELEMENT Name (#PCDATA)> <!ELEMENT Dept (#PCDATA)> <!ELEMENT Title (#PCDATA)> ]> <employee> <Name>John Goodman</Name> <Dept>Manufacturing</Dept> <Title>Supervisor</Title> </employee>
<?xml version="1.0" standalone="no"?> <!DOCTYPE family SYSTEM "family.dtd"> <family lastname="Smith"> <member memberid="m1">Sarah</member> <member memberid="m2">Bob</member> <member memberid="m3" mom="m1" dad="m2">Joanne</member> <member memberid="m4" mom="m1" dad="m2">Jim</member> </family>
<!ELEMENT family (member*)> <!ATTLIST family lastname CDATA #REQUIRED> <!ELEMENT member (#PCDATA)> <!ATTLIST member memberid ID #REQUIRED> <!ATTLIST member dad IDREF #IMPLIED> <!ATTLIST member mom IDREF #IMPLIED>
<?xml version="1.0"?> <!-- Identity transformation --> <xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0"> <xsl:template match="*|@*|comment()|processing-instruction()|text()"> <xsl:copy> <xsl:apply-templates select="*|@*|comment()|processing-instruction()|text()"/> </xsl:copy> </xsl:template> </xsl:stylesheet>
<!DOCTYPE doc [ <!ELEMENT doc (child*)> <!ATTLIST doc xmlns:nsprefix CDATA #IMPLIED> <!ATTLIST doc xmlns CDATA #IMPLIED> <!ATTLIST doc nsprefix:a1 CDATA #IMPLIED> <!ELEMENT child (#PCDATA)> ]> <doc nsprefix:a1 = "v1" xmlns="http://www.w3c.org" xmlns:nsprefix="http://www.oracle.com"> <child> This element inherits the default Namespace of doc. </child> </doc>
To write DOM based parser applications you can use the following classes:
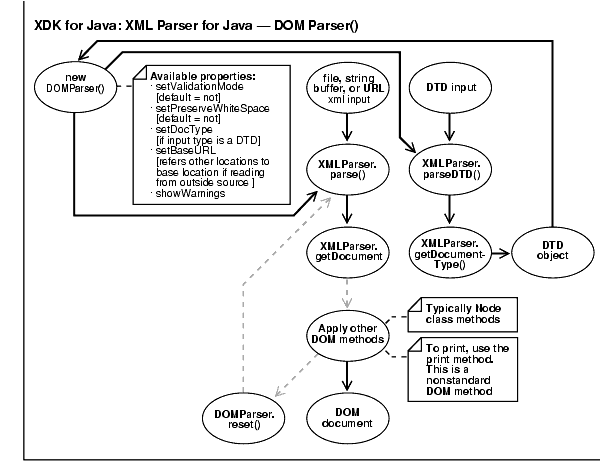
Since DOMParser extends XMLParser, all methods of XMLParser are also available to DOMParser. Figure 4-4 shows the main steps you need when coding with the DOMParser() class:
DOMParser() class is called. Available properties to use with this class are:
DOMParser.reset() to clean up any internal data structures, once the Parser has finished building the DOM tree.DOMParser() class is called. The available properties to apply to this class are:
XMLParser.parseDTD() method along with the DTD input.XMLParser.getDocumentType() method then sends the resulting DTD object back to the new DOMParser() and the process continues until the DTD has been applied.The example, "XML Parser for Java Example 1: Using the Parser and DOM API", shows hoe to use DOMParser() class.
The examples represent the way we write code so it is required to present the examples with Java coding standards (like all imports expanded), with documentation headers before the methods, and so on.
// This file demonstates a simple use of the parser and DOM API. // The XML file given to the application is parsed. // The elements and attributes in the document are printed. // This demonstrates setting the parser options. // import java.io.*; import java.net.*; import org.w3c.dom.*; import org.w3c.dom.Node; import oracle.xml.parser.v2.*; public class DOMSample { static public void main(String[] argv) { try { if (argv.length != 1) { // Must pass in the name of the XML file. System.err.println("Usage: java DOMSample filename"); System.exit(1); } // Get an instance of the parser DOMParser parser = new DOMParser(); // Generate a URL from the filename. URL url = createURL(argv[0]); // Set various parser options: validation on, // warnings shown, error stream set to stderr. parser.setErrorStream(System.err); parser.setValidationMode(DTD_validation); parser.showWarnings(true); // Parse the document. parser.parse(url); // Obtain the document. XMLDocument doc = parser.getDocument(); // Print document elements System.out.print("The elements are: "); printElements(doc); // Print document element attributes System.out.println("The attributes of each element are: "); printElementAttributes(doc); parser.reset(); } catch (Exception e) { System.out.println(e.toString()); } } static void printElements(Document doc) { NodeList nl = doc.getElementsByTagName("*"); Node n; for (int i=0; i<nl.getLength(); i++) { n = nl.item(i); System.out.print(n.getNodeName() + " "); } System.out.println(); } static void printElementAttributes(Document doc) { NodeList nl = doc.getElementsByTagName("*"); Element e; Node n; NamedNodeMap nnm; String attrname; String attrval; int i, len; len = nl.getLength(); for (int j=0; j < len; j++) { e = (Element)nl.item(j); System.out.println(e.getTagName() + ":"); nnm = e.getAttributes(); if (nnm != null) { for (i=0; i<nnm.getLength(); i++) { n = nnm.item(i); attrname = n.getNodeName(); attrval = n.getNodeValue(); System.out.print(" " + attrname + " = " + attrval); } } System.out.println(); } } static URL createURL(String fileName) { URL url = null; try { url = new URL(fileName); } catch (MalformedURLException ex) { File f = new File(fileName); try { String path = f.getAbsolutePath(); String fs = System.getProperty("file.separator"); if (fs.length() == 1) { char sep = fs.charAt(0); if (sep != '/') path = path.replace(sep, '/'); if (path.charAt(0) != '/') path = '/' + path; } path = "file://" + path; url = new URL(path); } catch (MalformedURLException e) { System.out.println("Cannot create url for: " + fileName); System.exit(0); } } return url; } }
See also Figure 4-4. The following provides comments for Example 1:
DOMParser(). In Example 1, see the line:
DOMParser parser = new DOMParser();
This class has several properties you can use. Here the example uses:
parser.setErrorStream(System.err); parser.setValidationMode(DTD_validation); parser.showWarnings(true);
URL url = createURL(argv[0])
parser.parse(url);
XMLDocument doc = parser.getDocument();
Figure 4-3 illustrates the main processes involved when parsing an XML document using the DOM interface. The DOMNamespace() method is applied in the parser process at the "bubble" that states "Apply other DOM methods". The following example illustrates how to use DOMNamespace():
// This file demonstates a simple use of the parser and Namespace // extensions to the DOM APIs. // The XML file given to the application is parsed and the // elements and attributes in the document are printed. // import java.io.*; import java.net.*; import oracle.xml.parser.v2.DOMParser; import org.w3c.dom.*; import org.w3c.dom.Node; // Extensions to DOM Interfaces for Namespace support. import oracle.xml.parser.v2.XMLElement; import oracle.xml.parser.v2.XMLAttr; public class DOMNamespace { static public void main(String[] argv) { try { if (argv.length != 1) { // Must pass in the name of the XML file. System.err.println("Usage: DOMNamespace filename"); System.exit(1); } // Get an instance of the parser Class cls = Class.forName("oracle.xml.parser.v2.DOMParser"); DOMParser parser = (DOMParser)cls.newInstance(); // Generate a URL from the filename. URL url = createURL(argv[0]); // Parse the document. parser.parse(url); // Obtain the document. Document doc = parser.getDocument(); // Print document elements printElements(doc); // Print document element attributes System.out.println("The attributes of each element are: "); printElementAttributes(doc); } catch (Exception e) { System.out.println(e.toString()); } } static void printElements(Document doc) { NodeList nl = doc.getElementsByTagName("*"); XMLElement nsElement; String qName; String localName; String nsName; String expName; System.out.println("The elements are: "); for (int i=0; i < nl.getLength(); i++) { nsElement = (XMLElement)nl.item(i); // Use the methods getQualifiedName(), getLocalName(), getNamespace() // and getExpandedName() in NSName interface to get Namespace // information. qName = nsElement.getQualifiedName(); System.out.println(" ELEMENT Qualified Name:" + qName); localName = nsElement.getLocalName(); System.out.println(" ELEMENT Local Name :" + localName); nsName = nsElement.getNamespace(); System.out.println(" ELEMENT Namespace :" + nsName); expName = nsElement.getExpandedName(); System.out.println(" ELEMENT Expanded Name :" + expName); } System.out.println(); } static void printElementAttributes(Document doc) { NodeList nl = doc.getElementsByTagName("*"); Element e; XMLAttr nsAttr; String attrname; String attrval; String attrqname; NamedNodeMap nnm; int i, len; len = nl.getLength(); for (int j=0; j < len; j++) { e = (Element) nl.item(j); System.out.println(e.getTagName() + ":"); nnm = e.getAttributes(); if (nnm != null) { for (i=0; i < nnm.getLength(); i++) { nsAttr = (XMLAttr) nnm.item(i); // Use the methods getQualifiedName(), getLocalName(), // getNamespace() and getExpandedName() in NSName // interface to get Namespace information. attrname = nsAttr.getExpandedName(); attrqname = nsAttr.getQualifiedName(); attrval = nsAttr.getNodeValue(); System.out.println(" " + attrqname + "(" + attrname + ")" + " = " + attrval); } } System.out.println(); } } static URL createURL(String fileName) { URL url = null; try { url = new URL(fileName); } catch (MalformedURLException ex) { File f = new File(fileName); try { String path = f.getAbsolutePath(); String fs = System.getProperty("file.separator"); if (fs.length() == 1) { char sep = fs.charAt(0); if (sep != '/') path = path.replace(sep, '/'); if (path.charAt(0) != '/') path = '/' + path; } path = "file://" + path; url = new URL(path); } catch (MalformedURLException e) { System.out.println("Cannot create url for: " + fileName); System.exit(0); } } return url; } }
Applications can register a SAX handler to receive notification of various parser events. XMLReader is the interface that an XML parser's SAX2 driver must implement. This interface enables an application to set and query features and properties in the parser, to register event handlers for document processing, and to initiate a document parse.
All SAX interfaces are assumed synchronous: the parse methods must not return until parsing is complete, and readers must wait for an event-handler callback to return before reporting the next event.
This interface replaces the (now deprecated) SAX 1.0 Parser interface. The XMLReader interface contains two important enhancements over the old Parser interface:
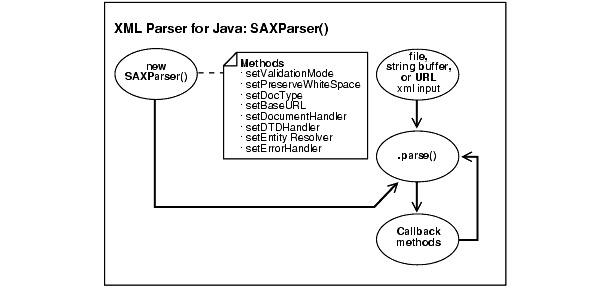
Table 4-1 lists the class SAXParser() methods.
Figure 4-5 shows the main steps for coding with the SAXParser() class.
SAXParser() class. Table 4-1 lists the available methods.The example, "XML Parser for Java Example 3: Using the Parser and SAX API (SAXSample.java)", illustrates how you can use SAXParser() class and several handler interfaces.
// This file demonstates a simple use of the parser and SAX API. // The XML file given to the application is parsed and // prints out some information about the contents of this file. // import org.xml.sax.*; import java.io.*; import java.net.*; import oracle.xml.parser.v2.*; public class SAXSample extends HandlerBase { // Store the locator Locator locator; static public void main(String[] argv) { try { if (argv.length != 1) { // Must pass in the name of the XML file. System.err.println("Usage: SAXSample filename"); System.exit(1); } // (1) Create a new handler for the parser SAXSample sample = new SAXSample(); // (2) Get an instance of the parser Parser parser = new SAXParser(); // (3) Set Handlers in the parser parser.setDocumentHandler(sample); parser.setEntityResolver(sample); parser.setDTDHandler(sample); parser.setErrorHandler(sample); // (4) Convert file to URL and parse try { parser.parse(fileToURL(new File(argv[0])).toString()); } catch (SAXParseException e) { System.out.println(e.getMessage()); } catch (SAXException e) { System.out.println(e.getMessage()); } } catch (Exception e) { System.out.println(e.toString()); } } static URL fileToURL(File file) { String path = file.getAbsolutePath(); String fSep = System.getProperty("file.separator"); if (fSep != null && fSep.length() == 1) path = path.replace(fSep.charAt(0), '/'); if (path.length() > 0 && path.charAt(0) != '/') path = '/' + path; try { return new URL("file", null, path); } catch (java.net.MalformedURLException e) { throw new Error("unexpected MalformedURLException"); } } ////////////////////////////////////////////////////////////////////// // (5) Sample implementation of DocumentHandler interface. ////////////////////////////////////////////////////////////////////// public void setDocumentLocator (Locator locator) { System.out.println("SetDocumentLocator:"); this.locator = locator; } public void startDocument() { System.out.println("StartDocument"); } public void endDocument() throws SAXException { System.out.println("EndDocument"); } public void startElement(String name, AttributeList atts) throws SAXException { System.out.println("StartElement:"+name); for (int i=0;i<atts.getLength();i++) { String aname = atts.getName(i); String type = atts.getType(i); String value = atts.getValue(i); System.out.println(" "+aname+"("+type+")"+"="+value); } } public void endElement(String name) throws SAXException { System.out.println("EndElement:"+name); } public void characters(char[] cbuf, int start, int len) { System.out.print("Characters:"); System.out.println(new String(cbuf,start,len)); } public void ignorableWhitespace(char[] cbuf, int start, int len) { System.out.println("IgnorableWhiteSpace"); } public void processingInstruction(String target, String data) throws SAXException { System.out.println("ProcessingInstruction:"+target+" "+data); } ////////////////////////////////////////////////////////////////////// // (6) Sample implementation of the EntityResolver interface. ////////////////////////////////////////////////////////////////////// public InputSource resolveEntity (String publicId, String systemId) throws SAXException { System.out.println("ResolveEntity:"+publicId+" "+systemId); System.out.println("Locator:"+locator.getPublicId()+" "+ locator.getSystemId()+ " "+locator.getLineNumber()+" "+locator.getColumnNumber()); return null; } ////////////////////////////////////////////////////////////////////// // (7) Sample implementation of the DTDHandler interface. ////////////////////////////////////////////////////////////////////// public void notationDecl (String name, String publicId, String systemId) { System.out.println("NotationDecl:"+name+" "+publicId+" "+systemId); } public void unparsedEntityDecl (String name, String publicId, String systemId, String notationName) { System.out.println("UnparsedEntityDecl:"+name + " "+publicId+" "+ systemId+" "+notationName); } ////////////////////////////////////////////////////////////////////// // (8) Sample implementation of the ErrorHandler interface. ////////////////////////////////////////////////////////////////////// public void warning (SAXParseException e) throws SAXException { System.out.println("Warning:"+e.getMessage()); } public void error (SAXParseException e) throws SAXException { throw new SAXException(e.getMessage()); } public void fatalError (SAXParseException e) throws SAXException { System.out.println("Fatal error"); throw new SAXException(e.getMessage()); } }
// This file demonstrates a simple use of the Namespace extensions to // the SAX APIs. import org.xml.sax.*; import java.io.*; import java.net.URL; import java.net.MalformedURLException; // Extensions to the SAX Interfaces for Namespace support. import oracle.xml.parser.v2.XMLDocumentHandler; import oracle.xml.parser.v2.DefaultXMLDocumentHandler; import oracle.xml.parser.v2.NSName; import oracle.xml.parser.v2.SAXAttrList; import oracle.xml.parser.v2.SAXParser; public class SAXNamespace { static public void main(String[] args) { String fileName; //Get the file name if (args.length == 0) { System.err.println("No file Specified!!!"); System.err.println("USAGE: java SAXNamespace <filename>"); return; } else { fileName = args[0]; } try { // Create handlers for the parser // Use the XMLDocumentHandler interface for namespace support // instead of org.xml.sax.DocumentHandler XMLDocumentHandler xmlDocHandler = new XMLDocumentHandlerImpl(); // For all the other interface use the default provided by // Handler base HandlerBase defHandler = new HandlerBase(); // Get an instance of the parser SAXParser parser = new SAXParser(); // Set Handlers in the parser // Set the DocumentHandler to XMLDocumentHandler parser.setDocumentHandler(xmlDocHandler); // Set the other Handler to the defHandler parser.setErrorHandler(defHandler); parser.setEntityResolver(defHandler); parser.setDTDHandler(defHandler); try { parser.parse(fileToURL(new File(fileName)).toString()); } catch (SAXParseException e) { System.err.println(args[0] + ": " + e.getMessage()); } catch (SAXException e) { System.err.println(args[0] + ": " + e.getMessage()); } } catch (Exception e) { System.err.println(e.toString()); } } static public URL fileToURL(File file) { String path = file.getAbsolutePath(); String fSep = System.getProperty("file.separator"); if (fSep != null && fSep.length() == 1) path = path.replace(fSep.charAt(0), '/'); if (path.length() > 0 && path.charAt(0) != '/') path = '/' + path; try { return new URL("file", null, path); } catch (java.net.MalformedURLException e) { /* According to the spec this could only happen if the file /* protocol were not recognized. */ throw new Error("unexpected MalformedURLException"); } } private SAXNamespace() throws IOException { } } /*********************************************************************** Implementation of XMLDocumentHandler interface. Only the new startElement and endElement interfaces are implemented here. All other interfaces are implemented in the class HandlerBase. **********************************************************************/ class XMLDocumentHandlerImpl extends DefaultXMLDocumentHandler { public void XMLDocumentHandlerImpl() { } public void startElement(NSName name, SAXAttrList atts) throws SAXException { // Use the methods getQualifiedName(), getLocalName(), getNamespace() // and getExpandedName() in NSName interface to get Namespace // information. String qName; String localName; String nsName; String expName; qName = name.getQualifiedName(); System.out.println("ELEMENT Qualified Name:" + qName); localName = name.getLocalName(); System.out.println("ELEMENT Local Name :" + localName); nsName = name.getNamespace(); System.out.println("ELEMENT Namespace :" + nsName); expName = name.getExpandedName(); System.out.println("ELEMENT Expanded Name :" + expName); for (int i=0; i<atts.getLength(); i++) { // Use the methods getQualifiedName(), getLocalName(), getNamespace() // and getExpandedName() in SAXAttrList interface to get Namespace // information. qName = atts.getQualifiedName(i); localName = atts.getLocalName(i); nsName = atts.getNamespace(i); expName = atts.getExpandedName(i); System.out.println(" ATTRIBUTE Qualified Name :" + qName); System.out.println(" ATTRIBUTE Local Name :" + localName); System.out.println(" ATTRIBUTE Namespace :" + nsName); System.out.println(" ATTRIBUTE Expanded Name :" + expName); // You can get the type and value of the attributes either // by index or by the Qualified Name. String type = atts.getType(qName); String value = atts.getValue(qName); System.out.println(" ATTRIBUTE Type :" + type); System.out.println(" ATTRIBUTE Value :" + value); System.out.println(); } } public void endElement(NSName name) throws SAXException { // Use the methods getQualifiedName(), getLocalName(), getNamespace() // and getExpandedName() in NSName interface to get Namespace // information. String expName = name.getExpandedName(); System.out.println("ELEMENT Expanded Name :" + expName); } }
oraxml is a command-line interface to parse an XML document. It checks for well-formedness and validity.
To use oraxml ensure the following:
xmlparserv2.jar file that comes with Oracle XML V2 parser for Java. Because oraxml supports schema validation, include xschema.jar also in your CLASSPATHUse the following syntax to invoke oraxml:
oraxml options source
oraxml expects to be given an XML file to parse. Table 4-2 lists oraxml's command line options.
The Java API for XML Processing (JAXP) gives you the ability to use the SAX, DOM, and XSLT processors from your Java application. JAXP enables applications to parse and transform XML documents using an API that is independent of a particular XML processor implementation.
JAXP has a pluggability layer that enables you to plug in an implementation of a processor. The JAXP APIs have an API structure consisting of abstract classes providing a thin layer for parser pluggability. Oracle has implemented JAXP based on the Sun Microsystems reference implementation.
| See Also:
More examples can be found at the URL
and in the directory |
import javax.xml.parsers.*; import javax.xml.transform.*; import javax.xml.transform.sax.*; import javax.xml.transform.dom.*; import javax.xml.transform.stream.*; import java.io.*; import java.util.*; import java.net.URL; import java.net.MalformedURLException; import org.xml.sax.*; import org.xml.sax.ext.*; import org.xml.sax.helpers.*; import org.w3c.dom.*; public class JAXPExamples { public static void main(String argv[]) throws TransformerException, TransformerConfigurationException, IOException, SAXException, ParserConfigurationException, FileNotFoundException { try { URL xmlURL = createURL("jaxpone.xml"); String xmlID = xmlURL.toString(); URL xslURL = createURL("jaxpone.xsl"); String xslID = xslURL.toString(); // System.out.println("--- basic ---"); basic(xmlID, xslID); System.out.println(); System.out.println("--- identity ---"); identity(xmlID); // URL generalURL = createURL("general.xml"); String generalID = generalURL.toString(); URL ageURL = createURL("age.xsl"); String ageID = ageURL.toString(); System.out.println(); System.out.println("--- namespaceURI ---"); namespaceURI(generalID, ageID); // System.out.println(); System.out.println("--- templatesHandler ---"); templatesHandler(xmlID, xslID); System.out.println(); System.out.println("--- contentHandler2contentHandler ---"); contentHandler2contentHandler(xmlID, xslID); System.out.println(); System.out.println("--- contentHandler2DOM ---"); contentHandler2DOM(xmlID, xslID); System.out.println(); System.out.println("--- reader ---"); reader(xmlID, xslID); System.out.println(); System.out.println("--- xmlFilter ---"); xmlFilter(xmlID, xslID); // URL xslURLtwo = createURL("jaxptwo.xsl"); String xslIDtwo = xslURLtwo.toString(); URL xslURLthree = createURL("jaxpthree.xsl"); String xslIDthree = xslURLthree.toString(); System.out.println(); System.out.println("--- xmlFilterChain ---"); xmlFilterChain(xmlID, xslID, xslIDtwo, xslIDthree); } catch(Exception err) { err.printStackTrace(); } } // public static void basic(String xmlID, String xslID) throws TransformerException, TransformerConfigurationException { TransformerFactory tfactory = TransformerFactory.newInstance(); Transformer transformer = tfactory.newTransformer(new StreamSource(xslID)); StreamSource source = new StreamSource(xmlID); transformer.transform(source, new StreamResult(System.out)); } // public static void identity(String xmlID) throws TransformerException, TransformerConfigurationException { TransformerFactory tfactory = TransformerFactory.newInstance(); Transformer transformer = tfactory.newTransformer(); transformer.setOutputProperty(OutputKeys.METHOD, "html"); transformer.setOutputProperty(OutputKeys.INDENT, "no"); StreamSource source = new StreamSource(xmlID); transformer.transform(source, new StreamResult(System.out)); } // public static void namespaceURI(String xmlID, String xslID) throws TransformerException, TransformerConfigurationException { TransformerFactory tfactory = TransformerFactory.newInstance(); Transformer transformer = tfactory.newTransformer(new StreamSource(xslID)); System.out.println("default: 99"); transformer.transform( new StreamSource(xmlID), new StreamResult(System.out)); transformer.setParameter("{http://www.oracle.com/ages}age", "20"); System.out.println(); System.out.println("should say: 20"); transformer.transform( new StreamSource(xmlID), new StreamResult(System.out)); transformer.setParameter("{http://www.oracle.com/ages}age", "40"); transformer.setOutputProperty(OutputKeys.METHOD, "html"); System.out.println(); System.out.println("should say: 40"); transformer.transform( new StreamSource(xmlID), new StreamResult(System.out)); } // public static void templatesHandler(String xmlID, String xslID) throws TransformerException, TransformerConfigurationException, IOException, SAXException, ParserConfigurationException, FileNotFoundException { TransformerFactory tfactory = TransformerFactory.newInstance(); if (tfactory.getFeature(SAXTransformerFactory.FEATURE)) { SAXTransformerFactory stfactory = (SAXTransformerFactory) tfactory; TemplatesHandler handler = stfactory.newTemplatesHandler(); handler.setSystemId(xslID); // JDK 1.1.8 Properties driver = System.getProperties(); driver.put("org.xml.sax.driver", "oracle.xml.parser.v2.SAXParser"); System.setProperties(driver); /** JDK 1.2.2 System.setProperty("org.xml.sax.driver", "oracle.xml.parser.v2.SAXParser"); */ XMLReader reader = XMLReaderFactory.createXMLReader(); reader.setContentHandler(handler); reader.parse(xslID); Templates templates = handler.getTemplates(); Transformer transformer = templates.newTransformer(); transformer.transform(new StreamSource(xmlID), new StreamResult(System.out)); } } // public static void reader(String xmlID, String xslID) throws TransformerException, TransformerConfigurationException, SAXException, IOException, ParserConfigurationException { TransformerFactory tfactory = TransformerFactory.newInstance(); SAXTransformerFactory stfactory = (SAXTransformerFactory)tfactory; StreamSource streamSource = new StreamSource(xslID); XMLReader reader = stfactory.newXMLFilter(streamSource); ContentHandler contentHandler = new oraContentHandler(); reader.setContentHandler(contentHandler); InputSource is = new InputSource(xmlID); reader.parse(is); } // public static void xmlFilter(String xmlID, String xslID) throws TransformerException, TransformerConfigurationException, SAXException, IOException, ParserConfigurationException { TransformerFactory tfactory = TransformerFactory.newInstance(); XMLReader reader = null; try { javax.xml.parsers.SAXParserFactory factory= javax.xml.parsers.SAXParserFactory.newInstance(); factory.setNamespaceAware(true); javax.xml.parsers.SAXParser jaxpParser= factory.newSAXParser(); reader = jaxpParser.getXMLReader(); } catch(javax.xml.parsers.ParserConfigurationException ex) { throw new org.xml.sax.SAXException(ex); } catch(javax.xml.parsers.FactoryConfigurationError ex1) { throw new org.xml.sax.SAXException(ex1.toString()); } catch(NoSuchMethodError ex2) { } if (reader == null) reader = XMLReaderFactory.createXMLReader(); XMLFilter filter = ((SAXTransformerFactory) tfactory).newXMLFilter(new StreamSource(xslID)); filter.setParent(reader); filter.setContentHandler(new oraContentHandler()); filter.parse(new InputSource(xmlID)); } // public static void xmlFilterChain( String xmlID, String xslID_1, String xslID_2, String xslID_3) throws TransformerException, TransformerConfigurationException, SAXException, IOException { TransformerFactory tfactory = TransformerFactory.newInstance(); if (tfactory.getFeature(SAXSource.FEATURE)) { SAXTransformerFactory stf = (SAXTransformerFactory)tfactory; XMLReader reader = null; try { javax.xml.parsers.SAXParserFactory factory = javax.xml.parsers.SAXParserFactory.newInstance(); factory.setNamespaceAware(true); javax.xml.parsers.SAXParser jaxpParser = factory.newSAXParser(); reader = jaxpParser.getXMLReader(); } catch(javax.xml.parsers.ParserConfigurationException ex) { throw new org.xml.sax.SAXException( ex ); } catch(javax.xml.parsers.FactoryConfigurationError ex1) { throw new org.xml.sax.SAXException( ex1.toString() ); } catch(NoSuchMethodError ex2) { } if (reader == null ) reader = XMLReaderFactory.createXMLReader(); XMLFilter filter1 = stf.newXMLFilter(new StreamSource(xslID_1)); XMLFilter filter2 = stf.newXMLFilter(new StreamSource(xslID_2)); XMLFilter filter3 = stf.newXMLFilter(new StreamSource(xslID_3)); if (filter1 != null && filter2 != null && filter3 != null) { filter1.setParent(reader); filter2.setParent(filter1); filter3.setParent(filter2); filter3.setContentHandler(new oraContentHandler()); filter3.parse(new InputSource(xmlID)); } } } // public static void contentHandler2contentHandler(String xmlID, String xslID) throws TransformerException, TransformerConfigurationException, SAXException, IOException { TransformerFactory tfactory = TransformerFactory.newInstance(); if (tfactory.getFeature(SAXSource.FEATURE)) { SAXTransformerFactory stfactory = ((SAXTransformerFactory) tfactory); TransformerHandler handler = stfactory.newTransformerHandler(new StreamSource(xslID)); Result result = new SAXResult(new oraContentHandler()); handler.setResult(result); XMLReader reader = null; try { javax.xml.parsers.SAXParserFactory factory= javax.xml.parsers.SAXParserFactory.newInstance(); factory.setNamespaceAware(true); javax.xml.parsers.SAXParser jaxpParser= factory.newSAXParser(); reader=jaxpParser.getXMLReader(); } catch( javax.xml.parsers.ParserConfigurationException ex ) { throw new org.xml.sax.SAXException( ex ); } catch( javax.xml.parsers.FactoryConfigurationError ex1 ) { throw new org.xml.sax.SAXException( ex1.toString() ); } catch( NoSuchMethodError ex2 ) { } if( reader == null ) reader = XMLReaderFactory.createXMLReader(); reader.setContentHandler(handler); reader.setProperty("http://xml.org/sax/properties/lexical-handler", handler); InputSource inputSource = new InputSource(xmlID); reader.parse(inputSource); } } // public static void contentHandler2DOM(String xmlID, String xslID) throws TransformerException, TransformerConfigurationException, SAXException, IOException, ParserConfigurationException { TransformerFactory tfactory = TransformerFactory.newInstance(); if (tfactory.getFeature(SAXSource.FEATURE) && tfactory.getFeature(DOMSource.FEATURE)) { SAXTransformerFactory sfactory = (SAXTransformerFactory) tfactory; DocumentBuilderFactory dfactory = DocumentBuilderFactory.newInstance(); DocumentBuilder docBuilder = dfactory.newDocumentBuilder(); org.w3c.dom.Document outNode = docBuilder.newDocument(); TransformerHandler handler = sfactory.newTransformerHandler(new StreamSource(xslID)); handler.setResult(new DOMResult(outNode)); XMLReader reader = null; try { javax.xml.parsers.SAXParserFactory factory = javax.xml.parsers.SAXParserFactory.newInstance(); factory.setNamespaceAware(true); javax.xml.parsers.SAXParser jaxpParser= factory.newSAXParser(); reader = jaxpParser.getXMLReader(); } catch(javax.xml.parsers.ParserConfigurationException ex) { throw new org.xml.sax.SAXException(ex); } catch(javax.xml.parsers.FactoryConfigurationError ex1) { throw new org.xml.sax.SAXException(ex1.toString()); } catch(NoSuchMethodError ex2) { } if(reader == null ) reader = XMLReaderFactory.createXMLReader(); reader.setContentHandler(handler); reader.setProperty("http://xml.org/sax/properties/lexical-handler", handler); reader.parse(xmlID); printDOMNode(outNode); } } // private static void printDOMNode(Node node) throws TransformerException, TransformerConfigurationException, SAXException, IOException, ParserConfigurationException { TransformerFactory tfactory = TransformerFactory.newInstance(); Transformer serializer = tfactory.newTransformer(); serializer.setOutputProperty(OutputKeys.METHOD, "xml"); serializer.setOutputProperty(OutputKeys.INDENT, "no"); serializer.transform(new DOMSource(node), new StreamResult(System.out)); } // private static URL createURL(String fileName) { URL url = null; try { url = new URL(fileName); } catch (MalformedURLException ex) { File f = new File(fileName); try { String path = f.getAbsolutePath(); // This is a bunch of weird code that is required to // make a valid URL on the Windows platform, due // to inconsistencies in what getAbsolutePath returns. String fs = System.getProperty("file.separator"); if (fs.length() == 1) { char sep = fs.charAt(0); if (sep != '/') path = path.replace(sep, '/'); if (path.charAt(0) != '/') path = '/' + path; } path = "file://" + path; url = new URL(path); } catch (MalformedURLException e) { System.out.println("Cannot create url for: " + fileName); System.exit(0); } } return url; } }
import org.xml.sax.ContentHandler; import org.xml.sax.Attributes; import org.xml.sax.SAXException; import org.xml.sax.Locator; public class oraContentHandler implements ContentHandler { private static final String TRADE_MARK = "Oracle 9i "; public void setDocumentLocator(Locator locator) { System.out.println(TRADE_MARK + "- setDocumentLocator"); } public void startDocument() throws SAXException { System.out.println(TRADE_MARK + "- startDocument"); } public void endDocument() throws SAXException { System.out.println(TRADE_MARK + "- endDocument"); } public void startPrefixMapping(String prefix, String uri) throws SAXException { System.out.println(TRADE_MARK + "- startPrefixMapping: " + prefix + ", " + uri); } public void endPrefixMapping(String prefix) throws SAXException { System.out.println(TRADE_MARK + " - endPrefixMapping: " + prefix); } public void startElement(String namespaceURI, String localName, String qName, Attributes atts) throws SAXException { System.out.print(TRADE_MARK + "- startElement: " + namespaceURI + ", " + namespaceURI + ", " + qName); int n = atts.getLength(); for(int i = 0; i < n; i++) System.out.print(", " + atts.getQName(i)); System.out.println(""); } public void endElement(String namespaceURI, String localName, String qName) throws SAXException { System.out.println(TRADE_MARK + "- endElement: " + namespaceURI + ", " + namespaceURI + ", " + qName); } public void characters(char ch[], int start, int length) throws SAXException { String s = new String(ch, start, (length > 30) ? 30 : length); if(length > 30) System.out.println(TRADE_MARK + "- characters: \"" + s + "\"..."); else System.out.println(TRADE_MARK + "- characters: \"" + s + "\""); } public void ignorableWhitespace(char ch[], int start, int length) throws SAXException { System.out.println(TRADE_MARK + "- ignorableWhitespace"); } public void processingInstruction(String target, String data) throws SAXException { System.out.println(TRADE_MARK + "- processingInstruction: " + target + ", " + target); } public void skippedEntity(String name) throws SAXException { System.out.println(TRADE_MARK + "- skippedEntity: " + name); } }
This section lists DTD questions and answers.
Answer: The DTD file defined in the <!DOCTYPE> declaration must be relative to the location of the input XML document. Otherwise, you'll need to use the setBaseURL(url) functions to set the base URL to resolve the relative address of the DTD if the input is coming from InputStream.
Answer: You need to include a reference to the applicable DTD in your XML document. Without it there is no way for the parser to know what to validate against. Including the reference is the XML standard way of specifying an external DTD. Otherwise you need to embed the DTD in your XML Document.
Do you have DTD caching? How do I set the DTD using version 2 of the parser for DTD Cache purpose?
Answer: Yes, DTD caching is optional and is not enabled automatically.
The method to set the DTD is setDoctype(). Here is an example:
// Test using InputSource parser = new DOMParser(); parser.setErrorStream(System.out); parser.showWarnings(true); FileReader r = new FileReader(args[0]); InputSource inSource = new InputSource(r); inSource.setSystemId(createURL(args[0]).toString()); parser.parseDTD(inSource, args[1]); dtd = (DTD)parser.getDoctype(); r = new FileReader(args[2]); inSource = new InputSource(r); inSource.setSystemId(createURL(args[2]).toString()); // ******************** parser.setDoctype(dtd); // ******************** parser.setValidationMode(DTD_validation); parser.parse(inSource);doc = (XMLDocument)parser.getDocument(); doc.print(new PrintWriter(System.out));
How does the XML Parser for Java version 2 recognize external DTDs when running from the server? The Java code has been loaded with loadjava and runs in the Oracle9i server process. My XML file has an external DTD reference.
resolveEntity()?Answer:
setBaseURL() method at this time.I would like to put all my DTDs in a JAR file, so that when the XML parser needs a DTD it can get it from the JAR. The current XML parser supports a base URL (setBaseURL()), but that just points to a place where all the DTDs are exposed.
Answer: The solution involves the following steps:
InputStream is = YourClass.class.getResourceAsStream("/foo/bar/your.dtd");
This will open ./foo/bar/your.dtd in the first relative location on the CLASSPATH that it can be found, including out of your JAR if it's in the CLASSPATH.
DOMParser d = new DOMParser(); d.parseDTD(is, "rootelementname"); d.setDoctype(d.getDoctype());
d.parse("yourdoc");
I am exporting Java objects to XML. I can construct a DOM with an XML document and use its print method to export it. However, I am unable to set the DTD of these documents. I construct a parser, parse the DTD, and then get the DTD through document doc = parser.getDocument() and DocType dtd = doc.getDocumentType().
How do I set the DTD of the freshly constructed XML documents to use this one in order to be able to check the correctness of the documents at a later time?
Answer: Your method of getting the DTD object is correct. However, we do not do any validation while creating the DOM tree using DOM APIs. So setting the DTD in the document will not help validate the DOM tree that is constructed. The only way to validate an XML file is to parse the XML document using the DOM parser or the SAX parser.
How do I parse and get a DTD object separately from parsing my XML document?
Answer: The parseDTD() method enables you to parse a DTD file separately and get a DTD object. Here is a sample code to do that:
DOMParser domparser = new DOMParser(); domparser.setValidationMode(DTD_validation); /* parse the DTD file */ domparser.parseDTD(new FileReader(dtdfile)); DTD dtd = domparser.getDocType();
The XML file has a tag like: <xn:subjectcode>. In the DTD, it is defined as <xn:subjectCode>. When the file is parsed and validated against the DTD, it returns the error: XML-0148: (Error) Invalid element 'xn:subjectcode' in content of 'xn:Resource',...
When I changed the element name to <xn:subjectCode> instead of <xn:subjectcode> it works. Is the parser case-sensitive as far as validation against DTDs go - or is it because, there is a namespace also in the tag definition of the element and when a element is defined along with its namespace, the case-sensitivity comes into effect?
Answer: XML is inherently case-sensitive, therefore our parsers enforce case sensitivity in order to be compliant. When you run in non-validation mode only well-formedness counts. However <test></Test> would signal an error even in non-validation mode.
Given:
<PAYLOAD> <![CDATA[<?xml version = '1.0' encoding = 'ASCII' standalone = 'no'?> <ADD_PO_003> <CNTROLAREA> <BSR> <VERB value="ADD">ADD</VERB> <NOUN value="PO">PO</NOUN> <REVISION value="003">003</REVISION> </BSR> </CNTROLAREA> </ADD_PO_003>]]> </PAYLOAD>
PAYLOAD to do extra processing on it?PAYLOAD it does not parse the data because it is in a CDATA section. Why?Answer:
The CDATA strategy is kind of odd. You won't be able to use a different encoding on the nested XML document included as text inside the CDATA, so having the XML declaration of the embedded document seems of little value to me. If you don't need the XML declaration, then why not just embed the message as real elements into the <PAYLOAD> instead of as a text chunk which is what CDATA does for you.
Just use the following code:
String s = YourDocumentObject.selectSingleNode("/OES_MESSAGE/PAYLOAD");
YourParser.parse( new StringReader(s));
where s is the string you got in the previous step.
<xsl:value-of select="/OES_MESSAGE/PAYLOAD" disable-output-escaping="yes"/>
I am having trouble creating a DTD and parsing it using Oracle XML Parser for Java version 2. I got the following error when I call DOMParser.parseDTD() function:
Attribute value should start with quote.
Please check my DTD and tell me what's wrong.
<?xml version = "1.0" encoding="UTF-8" ?> <!-- RCS_ID = "$Header: XMLRenderer.dtd 115.0 2000/09/18 03:00:10 fli noship $" --> <!-- RCS_ID_RECORDED = VersionInfo.recordClassVersion(RCS_ID, "oracle.apps.mwa.admin") --> <!-- Copyright: This DTD file is owned by Oracle Mobile Application Server Group. --> <!ELEMENT page (header?,form,footer?) > <!ATTLIST page name CDATA #REQUIRED lov (Y|N) 'N' > <!ELEMENT header EMPTY > <!ATTLIST header name CDATA #REQUIRED title CDATA home (Y|N) 'N' portal (Y|N) 'N' logout (Y|N) 'N' > <!ELEMENT footer EMPTY > <!ATTLIST footer name CDATA #REQUIRED home (Y|N) 'N' portal (Y|N) 'N' logout (Y|N) 'N' copyright (Y|N) 'N' > <!ELEMENT form (styledText|textInput|list|link|menu|submitButton|table|separator)+ > <!ATTLIST form name CDATA #REQUIRED title CDATA type CDATA > <!ELEMENT styledText (#PCDATA) > <!ELEMENT textInput EMPTY > <!ATTLIST textInput name CDATA #REQUIRED prompt CDATA #IMPLIED password (Y|N) 'N' required (Y|N) 'N' maxlength #IMPLIED size #IMPLIED format #IMPLIED default #IMPLIED > <!ELEMENT link (postfield*) > <!ATTLIST link name CDATA #REQUIRED title CDATA #REQUIRED baseurl CDATA #REQUIRED >
Answer: Your DTD syntax is not valid. When you declare ATTLIST with CDATA, you must put #REQUIRED, #IMPLIED, #FIXED, "any value", or%paramatic_entity. For example, your DTD contains:
<!ELEMENT header EMPTY > <!ATTLIST header name CDATA #REQUIRED title CDATA home (Y|N) 'N' portal (Y|N) 'N' logout (Y|N) 'N' >
should change as follows:
<!ELEMENT header EMPTY > <!ATTLIST header name CDATA #REQUIRED title CDATA #REQUIRED<!--can be replaced by #FIXED, #IMPLIED, or "title1" --> home (Y|N) 'N' portal (Y|N) 'N' logout (Y|N) 'N' >
Is there a standard extension (other than .xml or .txt) that should be used for external entities referenced in an XML document? These external entities are not complete XML files, but rather only part of an XML file, starting with the <![CDATA[ designation. Mostly they contain HTML, or Javascript code, but may also contain just some plain text. As an example, the external entity is A.txt which is being referenced in the XML document B.xml.
A.txt looks like this:
<![CDATA[<!-- This is just an html comment -->]]>
B.xml looks like this:
<?xml version="1.0"?> <!DOCTYPE B[ <!ENTITY htmlComment SYSTEM "A.txt"> ]> <B> &htmlComment; </B>
Currently we are using .txt as an extension for all such entities, but need to change that, otherwise the translation team assumes that these files need to get translated, whereas they don't. Is there a standard extension that we should be using?
Answer: The file extension for external entities is unimportant so you can change it to any convenient extension, including no extension.
How do I get the number of elements in a particular tag using the parser?
Answer: You can use the getElementsByTagName() method that returns a node list of all descent elements with a given tag name. You can then find out the number of elements in that node list to determine the number of the elements in the particular tag.
Answer: The parser accepts an XML-formatted document and constructs in memory a DOM tree based on its structure. It will then check whether the document is well-formed and optionally whether it complies with a DTD. It also provides methods to support DOM Level 1 and 2.
Answer: If you check the DOM spec referring to the table discussing the node type, you will find that if you are creating an element node, its node value is null and hence cannot be set. However, you can create a text node and append it to the element node. You can then put the value in the text node.
How to traverse the XML tree
Answer: You can traverse the tree by using the DOM API. Alternately, you can use the selectNodes() method which takes XPath syntax to navigate through the XML document. selectNodes() is part of oracle.xml.parser.v2.XMLNode.
How do I extract elements from the XML file?
Answer: If you're using DOM, the getElementsByTagName() method can be used to get all of the elements in the document.
If I add a DTD to an XML document, does it validate the DOM tree?
Answer: No, we do not do any validation while creating the DOM tree using the DOM APIs. So setting the DTD in the document will not help in validating the DOM tree that is constructed. The only way to validate an XML file is to parse the XML document using the DOM parser or SAX parser. Set the validation mode of the parser using setValidationMode().
How do I efficiently obtain the value of first child node of the element without going through the DOM tree?
Answer: If you do not need the entire tree, use the SAX interface to return the desired data. Since it is event-driven, it does not have to parse the whole document.
How do I create a DocType node?
Answer: The only current way of creating a doctype node is by using the parseDTD functions. For example, emp.dtd has the following DTD:
<!ELEMENT employee (Name, Dept, Title)> <!ELEMENT Name (#PCDATA)> <!ELEMENT Dept (#PCDATA)> <!ELEMENT Title (#PCDATA)>
You can use the following code to create a doctype node:
parser.parseDTD(new FileInputStream(emp.dtd), "employee"); dtd = parser.getDocType();
How do I use the selectNodes() method in XMLNode class?
Answer: The selectNodes() method is used in XMLElement and XMLDocument nodes. This method is used to extract contents from the tree or subtree based on the select patterns allowed by XSL. The optional second parameter of selectNodes, is used to resolve namespace prefixes (that is, it returns the expanded namespace URL given a prefix). XMLElement implements NSResolver, so it can be sent as the second parameter. XMLElement resolves the prefixes based on the input document. You can use the NSResolver interface, if you need to override the namespace definitions. The following sample code uses selectNodes
public class SelectNodesTest { public static void main(String[] args) throws Exception { String pattern = "/family/member/text()"; String file = args[0]; if (args.length == 2) pattern = args[1]; DOMParser dp = new DOMParser(); dp.parse(createURL(file)); // Include createURL from DOMSample XMLDocument xd = dp.getDocument(); XMLElement e = (XMLElement) xd.getDocumentElement(); NodeList nl = e.selectNodes(pattern, e); for (int i = 0; i < nl.getLength(); i++) { System.out.println(nl.item(i).getNodeValue()); } } } > java SelectNodesTest family.xml Sarah Bob Joanne Jim > java SelectNodesTest family.xml //member/@memberid m1 m2 m3 m4
I am using the SAX parser to parse an XML document. How does it get the value of the data?
Answer: During a SAX parse the value of an element will be the concatenation of the characters reported from after the startElement event to before the corresponding endElement event is called.
Inside the SAXSample program, I did not see any line that explicitly calls setDocumentLocator and some other methods. However, these methods are run. Can you explain when they are called and from where?
Answer: SAX is a standard interface for event-based XML parsing. The parser reports parsing events directly through callback functions such as setDocumentLocator() and startDocument(). The application, in this case, the SAXSample, uses handlers to deal with the different events. The following Web site is a good place to help you start learning about the event-driven API, SAX: http://www.megginson.com/SAX/index.html
Does the XML Parser DOMParser implement org.xml.sax.Parser interface? The documentation says it uses XML constants and the API does not include that class at all.
Answer: You'll want oracle.xml.parser.v2.SAXParser to work with SAX and to have something that implements the org.xml.sax.Parser interface.
I am trying to create a XML file on the fly. I use the NodeFactory to construct a document using createDocument(). I have then setStandalone("no") and setVersion("1.0"). When I try to add a DOCTYPE node with appendChild(new XMLNode("test", Node.DOCUMENT_TYPE_NODE)), I get a ClassCastException. How do I add a node of this type? I noticed that the NodeFactory did not have a method for creating a DOCTYPE node.
Answer: There is no way to create a new DOCUMENT_TYPE_NODE object using the DOM APIs. The only way to get a DTD object is to parse the DTD file or the XML file using the DOM parser, and then use the getDocType() method.
Note that new XMLNode("test",Node.DOCUMENT_TYPE_NODE) does not create a DTD object. It creates an XMLNode object with the type set to DOCUMENT_TYPE_NODE, which in fact should not be allowed. The ClassCastException is raised because appendChild expects a DTD object (based on the type).
Also, we do not do any validation while creating the DOM tree using the DOM APIs. So setting the DTD in the document will not help in validating the DOM tree that is constructed. The only way to validate an XML file is to parse the XML document using the DOM parser or the SAX Parser.
I am using the XML Parser for Java version 2. I want to obtain the value of first child node value of a tag. I could not find any method that can do that efficiently. The nearest match is method getElementsByTag("Name"), which traverses the entire tree under.
Answer: Your best bet, if you do not need the entire tree, is to use the SAX interface to return the desired data. Since it is event driven it does not have to parse the whole document.
Is there an example of XML document generation starting from information contained in simple variables? For example, a client fills a Java form and wants to obtain an XML document containing the given data.
Answer: Here are two possible interpretations of your question and answers to both. Let's say you have two variables in Java:
String firstname = "Gianfranco"; String lastname = "Pietraforte";
The two ways to get this information into an XML document are as follows:
String xml = "<person><first>"+firstname+"</first>"+ "<last>"+lastname+"</last></person"; DOMParser d = new DOMParser(); d.parse( new StringReader(xml)); Document xmldoc = d.getDocument();
Document xmldoc = new XMLDocument(); Element e1 = xmldoc.createElement("person"); xmldoc.appendChild(e1); Element e2 = xmldoc.createElement("first"); e1.appendChild(e2); Text t = xmldoc.createText(firstname); e2.appendChild(t); // and so on
Can you suggest how to get a print out using the DOM API in Java:
<name>macy</name>
I want to print out "macy". Don't know which class and what function to use. I was successful in printing "name" on to the console.
Answer: For DOM, you need to first realize that <name>macy</name> is actually an element named "name" with a child node (Text Node) of value "macy".
So, you can do the following:
String value = myElement.getFirstChild().getNodeValue();
We have a hash table of key value pairs, how do we build an XML file out of it using the DOM API? We have a hashtable key = value name = george zip = 20000. How do we build this?
<key>value</key><name>george</name><zip>20000</zip>'
Answer:
enum.hasMoreElements().createElement() on DOM document to create an element by the name of the key with a child text node with the value of the *value* of the hash table entry for that key.I have a question regarding our XML parser (version 2) implementation. I have the following scenario:
Document doc1 = new XMLDocument(); Element element1 = doc1.creatElement("foo"); Document doc2 = new XMLDocument(); Element element2 = doc2.createElement("bar"); element1.appendChild(element2);
My question is whether or not we should get a DOM exception of WRONG_DOCUMENT_ERR on calling the appendChild() routine.
Answer: Yes, you should get this error, since the owner document of element1 is doc1 while that of element2 is doc2. AppendChild() only works within a single tree and you are dealing with two different ones.
In XSLSample.java that's shipped with the XML parser version 2:
DocumentFragment result = processor.processXSL(xsl, xml); // create an output document to hold the result out = new XMLDocument(); // create a dummy document element for the output document Element root = out.createElement("root"); out.appendChild(root); // append the transformed tree to the dummy document element root.appendChild(result);
Nodes root and result are created from different XML documents. Wouldn't this result in the WRONG_DOCUMENT_ERR when we try to append result to root?
Answer: This sample uses a document fragment that does not have a root node, therefore there are not two XML documents.
When appending a document fragment to a node, only the child nodes of the document fragment (but not the document fragment itself) are inserted. Wouldn't the parser check the owner document of these child nodes?
Answer: A document fragment should not be bound to a root node, since, by definition, a fragment could very well be just a list of nodes. The root node, if any, should be considered a single child. That is, you could for example take all the lines of an Invoice document, and add them into a ProviderOrder document, without taking the invoice itself. How do we create a document fragment without root? As the XSLT processor does, so that we can append it to other documents.
I get the following error:
oracle.xml.parser.XMLDOMException: Node cannot be modified while trying to set the value of a newly created node as below: String eName="Mynode"; XMLNode aNode = new XMLNode(eName, Node.ELEMENT_NODE); aNode.setNodeValue(eValue);
How do I create a node whose value I can set later on?
Answer: You will see that if you are creating an element node, its nodeValue is null and hence cannot be set.
I receive the following error when reading the attached file using the SAX parser: if character data starts with a whitespace, characters() method discards characters that follow whitespace.
Is this a bug or can I force the parser to not discard those characters?
Answer: Use XMLParser.setPreserveWhitespace(true) to force the parser to not discard whitespace.
I have an XML string containing the following reference to a DTD, that is physically located in the directory where I start my program. The validating XML parser returns a message that this file cannot be found.
<!DOCTYPE xyz SYSTEM "xyz.dtd" >
What are the rules for locating DTDs on the disk?
Answer: Are you parsing an InputStream or a URL? If you are parsing an InputStream, the parser doesn't know where that InputStream came from so it cannot find the DTD in the "same directory as the current file". The solution is to setBaseURL()on DOMParser() to give the parser the URL hint information to be able to derive the rest when it goes to get the DTD.
Can multiple threads use a single XSLProcessor/XSLStylesheet instance to perform concurrent transformations?
Answer: As long as you are processing multiple files with no more than one XSLProcessor/XSLStylesheet instance for each XML file you can do this simultaneously using threads. If you take a look at the readme.html file in the bin directory, it describes ORAXSL which has a threads parameter for multithreaded processing.
Is it safe to use clones of a document in multiple threads? Is the public void setParam(String,String) throws XSLExceptionmethod of Class oracle.xml.parser.v2.XSLStylesheet supported? If no, is there another way to pass parameters at runtime to the XSLT processor?
Answer: If you are copying the global area set up by the constructor to another thread then it should work.
That method is supported since XML parser release 2.0.2.5.
I have some XML documents with ISO-8859-1 encoding. I am trying to parse these with the XML parser SAX API. In characters (char[], int, int), I would like to output the content in ISO-8859-1 (Latin1) too.
With System.out.println() it doesn't work correctly. German umlauts result in '?' in the output stream. What do I have to do to get the output in Latin1? The host system here is a SolarisTM Operating Environment 2.6.
Answer: You cannot use System.out.println(). You need to use an output stream which is encoding aware, for example, OutputStreamWriter.
You can construct an outputstreamwriter and use the write(char[], int, int) method to:
print.Ex:OutputStreamWriter out = new OutputStreamWriter(System.out, "8859_1"); /* Java enc string for ISO8859-1*/
I'm having trouble with parsing XML stored in NCLOB column using UTF-8 encoding. Here is what I'm running:
The following XML sample that I loaded into the database contains two UTF-8 multibyte characters:
<?xml version="1.0" encoding="UTF-8"?> <G> <A>GÂ,otingen, Brück_W</A> </G>
The text is supposed to be:
G(0xc2, 0x82)otingen, Br(0xc3, 0xbc)ck_W
If I am not mistaken, both multibyte characters are valid UTF-8 encodings and they are defined in ISO-8859-1 as:
0xC2 LATIN CAPITAL LETTER A WITH CIRCUMFLEX 0xFC LATIN SMALL LETTER U WITH DIAERESIS
I wrote a Java stored function that uses the default connection object to connect to the database, runs a Select query, gets the OracleResultSet, calls the getCLOB() method and calls the getAsciiStream() method on the CLOB object. Then it executes the following piece of code to get the XML into a DOM object:
DOMParser parser = new DOMParser(); parser.setPreserveWhitespace(true); parser.parse(istr); // istr getAsciiStreamXMLDocument xmldoc = parser.getDocument();
Before the stored function can do other tasks, this code throws an exception stating that the preceding XML contains invalid UTF-8 encoding.
0xc2, 0x82) from the XML, it parses fine.I loaded the sample XML into the database using the thin JDBC driver. I tried two database configurations with WE8ISO8859P1/WE8ISO8859P1 and WE8ISO8859P1/UTF8 and both showed the same problem.
Answer: Yes, the character (0xc2, 0x82) is valid UTF-8. We suspect that the character is distorted when getAsciiStream() is called. Try to use getUnicodeStream() and getBinaryStream() instead of getAsciiStream().
If this does not work, try to print out the characters to make sure that they are not distorted before they are sent to the parser in step: parser.parse(istr)
I've got Japanese data stored in an nvarchar2 field in the database. I have a dynamic SQL procedure that uses the PL/SQL web toolkit that enables me to access data using OAS and a browser. This procedure uses the XML parser to correctly format the result set in XML before returning it to the browser.
My problem is that the Japanese data is returned and displayed on the browser as upside down question marks. Is there anything I can do so that this data is correctly returned and displayed as Kanji?
Answer: Unfortunately, the Java and XML default character set is UTF-8 while I haven't heard of any UTF-8 operating systems nor people using it as in their database and people writing their web pages in UTF-8. All this means is that you have a character code conversion problem. The answer to your last question is yes. We do have both PL/SQL and Java XML parsers working in Japanese. Unfortunately, we cannot provide a simple solution that will fit in this space.
This is my XML document:
Documento de Prueba de gestin de contenidos. Roberto P0/00rez Lita
This is the way in which I parse the document:
DOMParser parser=new DOMParser(); parser.setPreserveWhitespace(true); parser.setErrorStream(System.err); parser.setValidationMode(false); parser.showWarnings(true); parser.parse ( new FileInputStream(new File("PruebaA3Ingles.xml")));
I get the following error:
XML-0231 : (Error) Encoding 'UTF-16' is not currently supported
I am using the XML Parser for Java version 2 and I am confused because the documentation says that the UTF-16 encoding is supported in this version of the Parser. Does anybody know how can I parse documents containing Spanish accents?
Answer: Oracle just uploaded a new release of the version 2 parser. It should support UTF-16. However, other utilities still have some problems with UTF-16 encoding.
I need to store accented characters in my XML documents. If I manually add an accented character, for example, an é, to my XML file and then attempt to parse the XML doc with the XML Parser for Java, the parser throws the following exception:
'Invalid UTF-8 encoding'
Here's the encoding declaration in my XML header:
<?xml version="1.0" encoding="UTF-8"?>
Also, if I specify UTF-16 as the default encoding the parser states that UTF-16 is not currently supported. From within my Java program if I define a Java string object as follows:
String name = "éééé";
and programmatically generate an XML document and save it to file then the é character is correctly written out to file. Can you tell me how I can successfully read in character data consisting of accented characters? I know that I can read in accented characters once I represent them in their hex or decimal format within the XML document, for example:
é
but I'd prefer not to do this.
Answer: You need to set the encoding based on the character set you were using when you created the XML file - I ran into this problem and solved it by setting the encoding to ISO-8859-1 (Western European ASCII) - you may need to use something different depending on the tool or operating system you are using.
If you explicitly set the encoding to UTF-8 (or do not specify it at all), the parser interprets your accented character (which has an ASCII value > 127) as the first byte of a UTF-8 multibyte sequence. If the subsequent bytes do not form a valid UTF-8 sequence, you get this error.
This error just means that your editor is not saving the file with UTF-8 encoding. For example, it might be saving it with ISO-8859-1 encoding. Remember that the encoding is a particular scheme used to write the Unicode character number representation to disk. Just adding the string to the top of the document like:
<?xml version="1.0" encoding="UTF-8"?>
does not cause your editor to write out the bytes representing the file to disk using UTF-8 encoding. I believe Notepad uses UTF-8, so you might try that.
I am trying to add an XML document as a child to an existing element. Here's an example:
import org.w3c.dom.*; import java.util.*; import java.io.*; import java.net.*; import oracle.xml.parser.v2.*; public class ggg {public static void main (String [] args) throws Exception { new ggg().doWork();; public void doWork() throws Exception {XMLDocument doc1 = new XMLDocument(); Element root1=doc1.createElement("root1"); XMLDocument doc2= new XMLDocument();Element root2=doc2.createElement("root2"); root1.appendChild(root2); doc1.print(System.out);};};
This reports:
D:\Temp\Oracle\sample>c:\jdk1.2.2\bin\javac -classpath D:\Temp\Oracle\lib\xmlparserv2.jar;. ggg.javaD:\Temp\Oracle\sample>c:\jdk1.2.2\bin\java -classpath D:\Temp\Oracle\lib\xmlparserv2.jar;. gggException in thread "main" java.lang.NullPointerException at oracle.xml.parser.v2.XMLDOMException.(XMLDOMException.java:67) at oracle.xml.parser.v2.XMLNode.checkDocument(XMLNode.java:919) at oracle.xml.parser.v2.XMLNode.appendChild(XMLNode.java, Compiled Code) at oracle.xml.parser.v2.XMLNode.appendChild(XMLNode.java:494) at ggg.doWork(ggg.java:20) at ggg.main(ggg.java:12)
Answer 1: The following works for me:
DocumentFragment rootNode = new XMLDocumentFragment(); DOMParser d = new DOMParser(); d.parse("http://.../pfgrfff.xml"); Document doc = d.getDocument(); Element e = doc.getDocumentElement(); // Important to remove it from the first doc // before adding it to the other doc. doc.removeChild(e); rootNode.appendChild(e);
You need to use the DocumentFragment class to do this as a document cannot have more than one root.
Answer 2: Actually, isn't this specifically a problem with appending a node created in another document, since all nodes contain a reference to the document they are created in. While DocumentFragment solves this, it isn't a more than one root problem, is it? Is there a quick or easy way to convert a com.w3c.dom.Document to org.w3c.dom.DocumentFragment?
I have this piece of code:
XSLStylesheet XSLProcessorStylesheet = new XSLStylesheet(XSLProcessorDoc, XSLProcessorURL); XSLStylesheet XSLRendererStylesheet = new XSLStylesheet(XSLRendererDoc, XSLRendererURL); XSLProcessor processor = new XSLProcessor(); // configure the processorprocessor.showWarnings(true); processor.setErrorStream(System.err); XMLDocumentFragment processedXML = processor.processXSL(XSLProcessorStylesheet, XMLInputDoc); XMLDocumentFragment renderedXML = processor.processXSL(XSLRendererStylesheet, processedXML); Document resultXML = new XMLDocument(); resultXML.appendChild(renderedXML);
The last line causes an exception in thread "main" oracle.xml.parser.v2.
XMLDOMException: Node of this type cannot be added.
Do I have to create a root element every time, even if I know that the resulting document fragment is a well formed XML document having only one root element?
Answer: It happens, as you have guessed, because a fragment can have more than one root element (for lack of a better term). In order to work around this, use the node functions to extract the one root element from your fragment and cast it into an
I get an error message when I try installing the XML parser:
loadjava -user username/manager -r -v xmlparserv2.jar Error: Exception in thread "main" java.lang.NoClassDefFounderr: oracle/jdbc/driver/OracleDriver at oracle.aurora.server.tools.
Answer: This is a failure to find the JDBC classes111.zip in your CLASSPATH. The loadjava utility connects to the database to load your classes using the JDBC driver.
I checked 'loadjava' and the path to classes111.zip is
<ORACLE_HOME>/jdbc/lib/classes111.zip
In version 8.1.6, classes111.zip resides in:
<ORACLE_HOME/jdbc/admin
How do I uninstall a version of the XML Parser and install a newer version? I know that there is something like dropjava, but still there are other packages which are loaded into the schema. I want to clean out the earlier version and install the new version in a clean manner.
Answer: You'll need to write SQL based on the USER_OBJECTS table where:
SELECT 'drop java class '''| | dbms_java.longname(object_name)| |''';
from user_objects where
OBJECT_TYPE = 'JAVA CLASS'and DBMS_JAVA.LONGNAME(OBJECT_NAME) LIKE 'oracle/xml/parser/%'
This will return a set of DROP JAVA CLASS commands which you can capture in a file using the SQL*Plus command SPOOL somefilenamecommand.
Then, run that spool file as a SQL script and all the right classes will be dropped.
Answer: The parser accepts any XML document giving you a tree-based API (DOM) to access or modify the document's elements and attributes. It also includes an event API (SAX) that provides a listener to be registered, and report specific elements or attributes and other document events.
Answer: You need to create an XSL stylesheet to render your XML into HTML. You can start with an HTML document in your desired format and populated with dummy data. Then you can replace this data with the XSLT commands that will populate the HTML with data from the XML document completing your stylesheet.
Does the XML Parser version 2 validate against an XML Schema?
Answer: Yes.
How do I include binary data in an XML document?
Answer: There is no way to directly include binary data within the document; however, there are two ways to work around this:
Answer: XML Schema is a W3C XML standards effort to bring the concept of data types to XML documents and in the process replace the syntax of DTDs to one based on XML. For more details, visit the following Web sites:
http://www.w3.org/TR/xmlschema-1/
http://www.w3.org/TR/xmlschema-2/
XML Schema is supported in Oracle9i and higher.
Answer: Oracle has representatives participating actively in the following 3C Working Groups related to XML/XSL: XML Schema, XML Query, XSL, XLink/XPointer, XML Infoset, DOM, and XML Core.
How do I determine the version number of the XDK toolkit that I downloaded?
Answer: You can find out the full version number by looking at the readme.html file included in the archive and linked to the Release Notes page.
Answer: The current XML parsers support Namespaces. Schema support is provided in Oracle9i and higher.
Can I use JDK 1.1.x with XML Parser v2 for Java?
Answer: Version 2 of the XML Parser for Java has nothing to do with Java2. It is simply a designation that indicates that it is not backward compatible with the version 1 parser and that it includes XSLT support. Version 2 of the parser will work fine with JDK 1.1.x.
I have a set of 100 records, and I am showing 10 at a time. On each column name I have made a link. When that link is clicked, I want to sort the data in the page alone, based on that column. How do I go about this?
Answer: If you are writing for IE5 alone and receiving XML data, you could just use Microsoft's XSL to sort data in a page. If you are writing for another browser and the browser is getting the data as HTML, then you have to have a sort parameter in XSQL script and use it in ORDER BY clause. Just pass it along with the skip-rows parameter.
Answer: XML Parser for Java can be used with any of the supported version JavaVMs. The only difference with Oracle9i is that you can load it into the database and use JServer, which is an internal JVM. For other database versions or servers, you simply run it in an external JVM and as necessary connect to a database through JDBC.
Answer: No, you need to include the proper encoding declaration in your document according to the specification. You cannot use setEncoding() to set the encoding for you input document. SetEncoding() is used with oracle.xml.parser.v2.XMLDocument to set the correct encoding for the printing.
Answer: We do not currently have any method that can directly parse an XML document contained within a string. You would need to convert the string into an InputStream or InputSource before parsing. An easy way is to create a ByteArrayInputStream using the bytes in the string.
Answer: If you are using IE5 as your browser you can display the XML document directly. Otherwise, you can use the Oracle XSLT Processor version 2 to create the HTML document using an XSL Stylesheet. The Oracle XML Transviewer bean also enables you to view your XML document.
Answer: You can't use System.out.println(). You need to use an output stream which is encoding aware (for example, OutputStreamWriter). You can construct an OutputStreamWriter and use the write(char[], int, int) method to print.
/* Example */ OutputStreamWriter out = new OutputStreamWriter (System.out, "8859_1"); /* Java enc string for ISO8859-1*/
How do I insert these characters in the XML documents: greater than (>), less than (<), apostrophe, double quotes, or equals (=)?
Answer: You need to use the entity references &eq; for equals (=), > for greater than (>), and < for less than (<). Use ' for an apostrophe or single quote. Use " for straight double quotes. Use & for ampersand.
I have a tag in XML <COMPANYNAME>
When we try to use A&B, the parser gives an error with invalid character. How do we use special characters when parsing companyname tag? We are using the Oracle XML Parser for C.
Answer: You can use special characters as part of XML name. For example: <A&B>abc</A&B>
If this is the case, using name entity doesn't solve the problem. According to XML 1.0 spec, NameChar and Name are defined as follows:
NameChar ::= Letter | Digit | '.' | '-' | '_' | ':' | CombiningChar |Extender Name ::= (Letter | '_' | ':') (NameChar)*
To answer your question, special characters such as &, $, and #, and so on are not allowed to be used as NameChar. Hence, if you are creating an XML document from scratch, you can use a workaround by using only valid NameChars. For example, <A_B>, <AB>, <A_AND_B> and so on.
They are still readable.
If you are generating XML from external data sources such as database tables, then this is a problem which XML 1.0 does not address.
In Oracle, the new type, XMLType, will help address this problem by offering a function which maps SQL names to XML names. This will address this problem at the application level. The SQL to XML name mapping function will escape invalid XML NameChar in the format of _XHHHH_ where HHHH is a Unicode value of the invalid character. For example, table name V$SESSION will be mapped to XML name V_X0024_SESSION.
Finally, escaping invalid characters is a workaround to give people a way to serialize names so that they can reload them somewhere else.
Answer: Check out the following example:
/* xmlDoc is a String of xml */ byte aByteArr [] = xmlDoc.getBytes(); ByteArrayInputStream bais = new ByteArrayInputStream (aByteArr, 0, aByteArr.length); domParser.parse(bais);
Answer: Here is an example to do that:
XMLDocument Your Document; /* Parse and Make Mods */ : StringWriter sw = new StringWriter(); PrintWriter pw = new PrintWriter(sw); YourDocument.print(pw); String YourDocInString = sw.toString();
Answer: Yes, since release 2.022, the XML Parser for Java provides an option to xsl:text to disable output escaping.
We need to be able to read and separate several XML documents as a single string. One solution would be to delimit these documents using some program-generated special character that we know for sure can never occur inside an XML document. The individual documents can then be easily tokenized and extracted or parsed as required.
Has any one else done this before? Any suggestions for what character can be used as the delimiter? For instance can characters in the range #x0-#x8 ever occur inside an XML document?
Answer: As far as legality is concerned, and if you limit it to 8-bit, then #x0-#x8; #xB, #xC, #xE, and #xF are not legal. However, this assumes that you preprocess the doc and do not depend upon exceptions as not all parsers reject all illegal characters.
The XML parser for Java does not expand entity references, such as &[whatever]. Instead, all values are null. How can I fix this?
Answer: You probably have a simple error defining or using your entities, since we have a number of regression tests that handle entity references fine. A simple example is: ]> Alpha, then &status.
We would like to break apart an arbitrary XML document and store it in the database without creating a DDL to insert. Is this possible?
Answer: In Oracle8i release 8.1.6 and higher, Oracle Text can do this.
Answer: No this is not possible. Either the schema must already exist or and XSL stylesheet to create the DDL from the XML must exist.
Answer: This is not possible with the current DOM1 specification. The DOM2 specification may address this.
As a workaround, you can use a DOM approach or an XSLT-based approach to accomplish this. If you use DOM, then you'll have to remove the node from one document before you append it into the other document to avoid ownership errors.
Here is an example of the XSL-based approach. Assume your two XML source files are:
demo1.xml
<messages> <msg> <key>AAA</key> <num>01001</num> </msg> <msg> <key>BBB</key> <num>01011</num> </msg> </messages>
demo2.xml
<messages> <msg> <key>AAA</key> <text>This is a Message</text> </msg> <msg> <key>BBB</key> <text>This is another Message</text> </msg> </messages>
Here is a stylesheet that joins demo1.xml to demo2.xml based on matching the <key> values.
demomerge.xsl
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:output indent="yes"/> <xsl:variable name="doc2" select="document('demo2.xml')"/> <xsl:template match="@*|node()"> <xsl:copy> <xsl:apply-templates select="@*|node()"/> </xsl:copy> </xsl:template> <xsl:template match="msg"> <xsl:copy> <xsl:apply-templates select="@*|node()"/> <text><xsl:value-of select="$doc2/messages/msg[key=current()/key]/text"/> </text> </xsl:copy> </xsl:template> </xsl:stylesheet>
If you use the command line oraxsl to test this, you would enter:
$ oraxsl demo1.xml demomerge.xsl
Then, you will get the following merged result:
<messages> <msg> <key>AAA</key> <num>01001</num> <text>This is a Message</text> </msg> <msg> <key>BBB</key> <num>01011</num> <text>This is another Message</text> </msg></messages>
This is obviously not as efficient for larger files as an equivalent database join between two tables, but this illustrates the technique if you have only XML files to work with.
I am using SAX to parse an XML document. How I can get the value of a particular tag? For example, in Java, how do I get the value for title? I know there are startElement, endElement, and characters methods.
Answer: During a SAX parse the value of an element will be the concatenation of the characters reported from after startElement to before the corresponding endElement is called.
We are using Oracle XML Parser for Java on Windows NT 4.0. When we are parsing an XML document with an external DTD we get the following error:
<!DOCTYPE listsamplereceipt SYSTEM "file:/E:/ORACLE/utl_file_dir/dadm/ae.dtd"> java.lang.SecurityExceptionat oracle.aurora.rdbms.SecurityManagerImpl.checkFile(SecurityManagerImpl.java)at oracle.aurora.rdbms.SecurityManagerImpl.checkRead(SecurityManagerImpl.java)at java.io.FileInputStream.<init>(FileInputStream.java)at java.io.FileInputStream.<init>(FileInputStream.java)at sun.net.www.MimeTable.load(MimeTable.java)at sun.net.www.MimeTable.<init>(MimeTable.java)at sun.net.www.MimeTable.getDefaultTable(MimeTable.java)at sun.net.www.protocol.file.FileURLConnection.connect(FileURLConnection.java)at sun.net.www.protocol.file.FileURLConnection.getInputStream(FileURLConnection. java)at java.net.URL.openStream(URL.java)at oracle.xml.parser.v2.XMLReader.openURL(XMLReader.java:2313)at oracle.xml.parser.v2.XMLReader.pushXMLReader(XMLReader.java:176)at ...
What is causing this?
Answer: Grant the JAVASYSPRIV role to your user running this code to allow it to open the external file or URL.
I am trying to include an external XML file in another XML file. Do the XML Parser for Java version 1 and version 2 support external parsed entities?
Answer: IE 5.0 will parse an XML file and show the parsed output. Just load the file as you would an HTML page.
The following works, both browsing it in IE5 as well as parsing it with the XML Parser for Java version 2. Even though I'm sure it works fine in the XML Parser for Java version 1, you should be using the latest parser version as it is faster than version 1.
File: a.xml <?xml version="1.0" ?> <!DOCTYPE a [<!ENTITY b SYSTEM "b.xml">]> <a>&b;</a> File: b.xml <ok/>
When I browse and parse a.xml I get the following:
<a> <ok/> </a>
We are using the XML Parser for Java version 1.0, because that is what is shipped to the customers with release 10.7 and 11.0 of our application. Can you refer me to this, or some other sample code to do this.
Shouldn't file b.xml be in the format:
<?xml version="1.0" ?> <b> <ok/> </b>
Does the Oracle XML Parser come with a utility to parse an XML file and see the parsed output?
Answer: Not strictly. The parsed external entity only needs to be a well-formed fragment. The following program (with xmlparser.jar from version 1) in your CLASSPATH shows parsing and printing the parsed document. It's parsing here from a string but the mechanism would be no different for parsing from a file, given its URL.
import oracle.xml.parser.*; import java.io.*; import java.net.*; import org.w3c.dom.*; import org.xml.sax.*; /* ** Simple Example of Parsing an XML File from a String ** and, if successful, printing the results. ** ** Usage: java ParseXMLFromString <hello><world/></hello> */ public class ParseXMLFromString { public static void main( String[] arg ) throws IOException, SAXException { String theStringToParse = "<?xml version='1.0'?>"+ "<hello>"+ " <world/>"+ "</hello>"; XMLDocument theXMLDoc = parseString( theStringToParse ); // Print the document out to standard out theXMLDoc.print(System.out); } public static XMLDocument parseString( String xmlString ) throws IOException, SAXException { XMLDocument theXMLDoc = null; // Create an oracle.xml.parser.v2.DOMParser to parse the document. XMLParser theParser = new XMLParser(); // Open an input stream on the string ByteArrayInputStream theStream = new ByteArrayInputStream( xmlString.getBytes() ); // Set the parser to work in non-Validating mode theParser.setValidationMode(DTD_validation); try { // Parse the document from the InputStream theParser.parse( theStream ); // Get the parsed XML Document from the parser theXMLDoc = theParser.getDocument(); } catch (SAXParseException s) { System.out.println(xmlError(s)); throw s; } return theXMLDoc; } private static String xmlError(SAXParseException s) { int lineNum = s.getLineNumber(); int colNum = s.getColumnNumber(); String file = s.getSystemId(); String err = s.getMessage(); return "XML parse error in file " + file + "\n" + "at line " + lineNum + ", character " + colNum + "\n" + err; } }
From where I can download oracle.xml.parser.v2.OraXSL?
Answer: It's part of our integrated XML Parser for Java version 2 release. Our XML Parser, DOM, XPath implementation, and XSLT engine are nicely integrated into a single cooperating package. To download it, please refer to the following Web site:
http://otn.oracle.com/tech/xml/xdk_java/
We are interested in using the Oracle database primarily to store XML. We would like to parse incoming XML documents and store data and tags in the database. We are concerned about the following two aspects of XML in Oracle:
First, the relational mapping of parsed XML data. We prefer hierarchical storage of parsed XML data. Is this a valid concern? Will XMLType in Oracle9i address this concern?
Second, a lack of an ambiguous content mode in the Oracle Parser for Java is limiting to our business. Are there plans to add an ambiguous content mode to the Oracle Parser for Java?
Answer: Many customers initially have this concern. It depends on what kind of XML data you are storing. If you are storing XML datagrams that are really just encoding of relational information (for example, a purchase order), then you will get much better performance and much better query flexibility (in SQL) to store the data contained in the XML documents in relational tables, then reproduce on-demand an XML format when any particular data needs to be extracted.
If you are storing documents that are mixed-content, like legal proceedings, chapters of a book, reference manuals, and so on, then storing the documents in chunks and searching them using Oracle Text's XML search capabilities is the best bet.
The book, Building Oracle XML Applications, by Steve Muench, covers both of these storage and searching techniques with lots of examples.
For the second point, the Oracle XML Parser implements all the XML 1.0 standard, and the XML 1.0 standard requires XML documents to have unambiguous content models. Therefore, there is no way a compliant XML 1.0 parser can implement ambiguous content models.
Can any one suggest good books for learning about XML and XSL?
Answer: There are many excellent articles, white papers, and books that describe all facets of XML technology. Many of these are available on the World Wide Web. The following are some of the most useful resources we have found:
http://metalab.unc.edu/pub/sun-info/standards/xml/why/xml apps.htmhttp://www.javaworld.com/jw-04-1999/jw-04-xml_p.htmlhttp://www.informatik.tu-darmstadt.de/DVS1/staff/bourret/ XML/http://www.w3.org/XML/http://www.xml.com/http://www.xml.com/axml/testaxml.htmhttp://www.ucc.ie/xml/ XML.orghttp://xml.org/http://xdev.datachannel.com/Answer: HP-UX ports for our C/C++ Parser as well as our C++ Class Generator are available. Look for an announcement on http://otn.oracle.com
Can we compress XML documents when saving them to the database as a CLOB? If they are compressed, what is the implication of using Oracle Text against the documents? We have large XML documents that range up to 1 MB and they need to be minimized.
The main requirement is to save cost in terms of disk storage as the XML documents stored are history information (more of a datawarehouse environment). We could save a lot of disk space if we could compress the documents before storage. The searching capability is only secondary, but a big plus.
Answer: The XDK for Java supports a compression mechanism in Oracle9i. It supports streaming compression and uncompression. The compression is achieved by removing the markup in the XML Document. The initial version does not support searching the compressed data. This is planned for a future release.
If you want to store and search your XML docs, Oracle Text can handle this. I am sure that the size of individual document is not a problem for Oracle Text.
If you want to compress the 1 MB docs for saving disk space and costs, Oracle Text will not be able to automatically handle a compressed XML document.
Try looking at XMLZip:
http://www.xmls.com/resources/xmlzip.xml?id=resources_xmlzip
My only concern would be the performance hit to do the uncompression. If you are just worried about transmitting the XML from client to server or vice versa, then HTTP compression could be easier.
I would like to generate an XML document based on two tables with a master detail relationship. Suppose I have two tables:
There is a master detail relationship between PARENT and CHILD. How can I generate a document that looks like this?
<?xml version = '1.0'?> <ROWSET> <ROW num="1"> <parent_name>Bill</parent_name> <child_name>Child 1 of 2</child_name> <child_name>Child 2 of 2</child_name> </ROW> <ROW num="2"> <parent_name>Larry</parent_name> <child_name>Only one child</child_name> </ROW> </ROWSET>
Answer: You should use an object view to generate an XML document from a master-detail structure. In your case, use the following code:
create type child_type is object (child_name <data type child_name>) ; / create type child_type_nst is table of child_type ; / create view parent_child as select p.parent_name , cast ( multiset ( select c.child_name from child c where c.parent_id = p.id ) as child_type_nst ) child_type from parent p /
A SELECT * FROM parent_child, processed by an SQL to XML utility would generate a valid XML document for your parent child relationship. The structure would not look like the one you have presented, though. It would look like this:
<?xml version = '1.0'?> <ROWSET> <ROW num="1"> <PARENT_NAME>Bill</PARENT_NAME> <CHILD_TYPE> <CHILD_TYPE_ITEM> <CHILD_NAME>Child 1 of 2</CHILD_NAME> </CHILD_TYPE_ITEM> <CHILD_TYPE_ITEM> <CHILD_NAME>Child 2 of 2</CHILD_NAME> </CHILD_TYPE_ITEM> </CHILD_TYPE> </ROW> <ROW num="2"> <PARENT_NAME>Larry</PARENT_NAME> <CHILD_TYPE> <CHILD_TYPE_ITEM> <CHILD_NAME>Only one child</CHILD_NAME> </CHILD_TYPE_ITEM> </CHILD_TYPE> </ROW> </ROWSET>
|
 Copyright © 2001, 2002 Oracle Corporation. All Rights Reserved. |
|

