| Oracle Data Guard Concepts and Administration Release 2 (9.2) Part Number A96653-02 |
|





|
View PDF |
| Oracle Data Guard Concepts and Administration Release 2 (9.2) Part Number A96653-02 |
|
|
View PDF |
Oracle9i provides the ability to perform true database archiving from a primary database to a standby database when either or both databases reside in a Real Application Clusters environment. This chapter summarizes the configuration requirements and considerations that apply when using Oracle Data Guard with Oracle Real Application Clusters databases. It contains the following sections:
You can configure a standby database to protect a primary database using Real Application Clusters. The following table describes the possible combinations of instances in the primary and standby databases:
| Instance Combinations | Single-Instance Standby Database | Multi-Instance Standby Database |
|---|---|---|
| Single-Instance Primary Database |
Yes |
Yes (for read-only queries) |
| Multi-Instance Primary Database |
Yes |
Yes |
In each scenario, each instance of the primary database archives its own online redo logs to the standby database.
Figure C-1 illustrates a Real Application Clusters database with two primary database instances (a multi-instance primary database) archiving redo logs to a single-instance standby database.
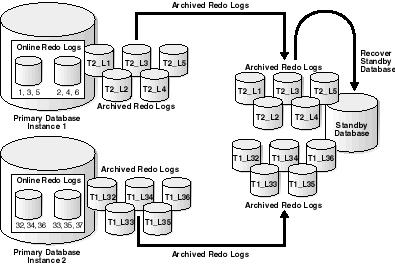
Text description of the illustration sbr81088.gif
In this case, Instance 1 of the primary database transmits logs 1, 2, 3, 4, 5 while Instance 2 transmits logs 32, 33, 34, 35, 36. If the standby database is in managed recovery mode, it automatically determines the correct order in which to apply the archived redo logs.
Perform the following steps to set up log transport services on the primary database:
SERVICE attribute of the LOG_ARCHIVE_DEST_n initialization parameter.The standby database also applies the archived redo log it receives through managed recovery to keep itself current with the primary database.
.| See Also:
Oracle9i Real Application Clusters Setup and Configuration for information about configuring a database for Real Application Clusters |
Perform the following steps to set up log transport services on a single instance standby database:
LOCATION attribute of the LOG_ARCHIVE_DEST_1 initialization parameter. If ARCH process is used in log transport services, define STANDBY_ARCHIVE_DEST and LOG_ARCHIVE_FORMAT to specify the location of archived redo logs.This next example shows a configuration where both primary and standby databases are in a Real Application Clusters environment. This allows you to separate the log transport services processing from the log apply services processing on the standby database, thereby improving overall primary and standby database performance. Figure C-2 illustrates a standby database configuration in a Real Application Clusters environment.
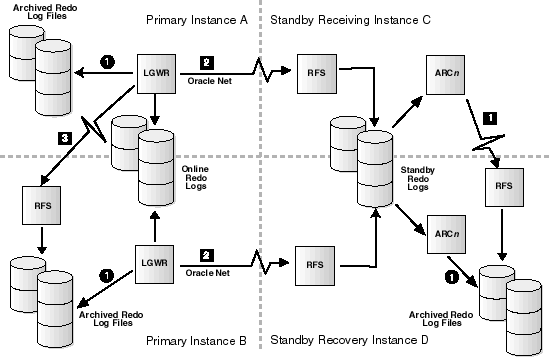
Text description of the illustration rac_arch.gif
In Figure C-2, the numbers within circles indicate local connections, and the numbers within boxes indicate remote connections.
When you use the standby database in a Real Application Clusters environment, any instance can receive archived logs from the primary database; this is the receiving instance. However, the archived logs must ultimately reside on disk devices accessible by the node on which the managed recovery operation is performed; this is the recovery instance. Transferring the standby database archived logs from the receiving instance to the recovery instance is achieved using the cross-instance archival operation, performed on the standby database.
The standby database cross-instance archival operation requires use of standby redo logs as the temporary repository of primary database archived logs. Using the standby redo logs not only improves standby database performance and reliability, but also allows the cross-instance archival operation to be performed. However, because standby redo logs are required for the cross-instance archival operation, the primary database must use the log writer process (LGWR) to perform the primary database archival operation.
When both your primary and standby databases are in a Real Application Clusters configuration, and the standby database is in managed recovery mode, then a single instance of the standby database applies all sets of logs transmitted by the primary instances. In this case, the standby instances that are not applying redo cannot be in read-only mode while managed recovery is in progress; in most cases, the nonrecoverable instances should be shut down, although they can also be mounted.
Perform the following steps to set up log transport services on the standby database:
LOCATION attribute of the LOG_ARCHIVE_DEST_1 initialization parameter.SERVICE attribute of the LOG_ARCHIVE_DEST_1 initialization parameter.Perform the following steps to set up log transport services on the primary database:
SERVICE attribute of the LOG_ARCHIVE_DEST_n initialization parameter.Ideally, each primary database instance should archive to a corresponding standby database instance. However, this is not required.
It is possible to set up a cross-instance archival database environment. Within a Real Application Clusters configuration, each instance directs its archived redo logs to a single instance of the cluster. This instance is called the recovery instance and is typically the instance where managed recovery is performed. This instance typically has a tape drive available for RMAN backup and restore support. Example C-1 shows how to set up the LOG_ARCHIVE_DEST_n initialization parameter for archiving redo logs across instances. Execute this example on all instances except the recovery instance.
SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_1 = `LOCATION=archivelog MANDATORY REOPEN=120'; SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_1 = enable; SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_2 = `SERVICE=prmy1 MANDATORY REOPEN=300'; SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_2 = enable;
Destination 1 is the repository containing the local archived redo logs required for instance recovery. This is a mandatory destination. Because the expected cause of failure is lack of adequate disk space, the retry interval is 2 minutes. This should be adequate to allow the DBA to purge unnecessary archived redo logs. Notification of destination failure is accomplished by manually searching the primary database alert log.
Destination 2 is the recovery instance on the primary database where RMAN is used to back up the archived redo logs from local disk storage to tape. This is a mandatory destination, with a reconnect threshold of 5 minutes. This is the time needed to fix any network-related failures. Notification of destination failure is accomplished by manually searching the primary or standby database alert log.
Cross-instance archiving is available using the ARCn process only. Using the LGWR process for cross-instance archiving results in the RFS process failing and the archive log destination being placed in the Error state.
This section contains the Data Guard configuration information that is specific to Real Application Clusters environment. It contains the following topics:
The format for archive log filenames are usually in the form of log_%parameter where %parameter can be one or more of the following:
| Parameter | Description |
|---|---|
|
%T |
Thread number, left-zero-padded |
|
%t |
Thread number, not padded |
|
%S |
Log sequence number, left-zero-padded |
|
%s |
Log sequence number, not padded |
For example, LOG_ARCHIVE_FORMAT = "log_%t_%s.arc". The thread parameters%t or %T are mandatory for Real Application Clusters in order to uniquely identify the archived redo logs with the LOG_ARCHIVE_FORMAT parameter.
You can specify the amount of physical storage on a disk device to be available for an archiving destination using the QUOTA_SIZE attribute of the LOG_ARCHIVE_DEST_n initialization parameter. An archive destination can be designated as being able to occupy all or some portion of the physical disk represented by the destination. For example, in a Real Application Clusters environment, a physical archived redo log disk device can be shared by two or more separate nodes (through a clustered file system, such as is available with Sun Clusters). As there is no cross-instance initialization parameter knowledge, none of the Real Application Clusters nodes is aware that the archived redo log physical disk device is shared with other instances. This leads to substantial problems when the destination disk device becomes full; the error is not detected until every instance tries to archive to the already full device. This seriously affects database availability.
In a Real Application Clusters configuration, any node that loses connectivity with a standby destination will cause all other members of the cluster to stop sending data to that destination (this maintains the data integrity of the data that has been transmitted to that destination and can be recovered).
When the failed standby destination comes back up, Data Guard runs the site in resynchronization mode until the primary and standby databases are identical (no gaps remain). Then, the standby destination can participate in the Data Guard configuration.
The following list describes the effect of the three data protection configurations in Real Application Clusters environment:
If a lost destination is the last participating standby site, then the instance on the node that loses connectivity will be shut down. Other nodes in a Real Application Clusters configuration that still have connectivity to the last standby site will recover the lost instance and continue sending to their standby site. Only when every node in a Real Application Clusters configuration loses connectivity to the last standby site will the configuration, including the primary database, be shut down.
|
Note: If you are running Real Application Clusters and Data Guard in maximum protection mode and you expect the network to be down for an extended period of time, consider changing the primary database to run in either the maximum availability or the maximum performance mode until network connectivity is restored. See Section C.3.2 for information about changing the primary database temporarily to run in the maximum availability or maximum performance mode. |
When a failover operation occurs to a site that is participating in the maximum protection configuration, all data that was ever committed on the primary database will be recovered on the standby site.
Losing the last standby destination does not cause the primary database instance to shut down.
When a failover operation occurs to a site that is participating in the maximum availability configuration, all data that was ever committed on the primary database and was successfully sent to the standby database will be recovered on the standby site.
Losing the last standby destination does not cause the primary database instance to shut down.
When a failover operation occurs to any standby site, data that was received from the primary database will be recovered on the standby database up to the last transactionally consistent point in time. In a single-instance configuration, this means all data received will be recovered. In a failover situation, it is possible to lose some transactions from one or more logs that have not yet been transmitted.
For a Real Application Clusters database, only one primary instance and one standby instance can be active during a switchover operation. Therefore, before a switchover operation, shut down all but one primary instance and one standby instance. After the switchover operation completes, restart the primary and standby instances that were shut down during the switchover operation.
Before performing a failover to a Real Application Clusters standby database, first shut down all but one standby instance. After the failover operation completes, restart the instances that were shutdown.
If you issue the SQL statement ALTER DATABASE RECOVER MANAGED STANDBY DATABASE FINISH SKIP STANDBY LOGFILE to force a standby database into the primary role, log apply services apply archived redo logs until the first unarchived redo log is encountered. All archived redo logs beyond this point are not recovered and all data in them is lost. In a Real Application Clusters environment, use of the FINISH SKIP STANDBY LOGFILE clause can result in additional data loss because multiple instances might have dependencies on the redo logs.
This section provides help troubleshooting problems with Real Application Clusters. It contains the following sections:
When your database is using Real Application Clusters, active instances prevent a switchover from being performed. When other instances are active, an attempt to switch over fails with the following error message:
SQL> ALTER DATABASE COMMIT TO SWITCHOVER TO STANDBY; ALTER DATABASE COMMIT TO SWITCHOVER TO STANDBY * ORA-01105: mount is incompatible with mounts by other instances
Action: Query the GV$INSTANCE view as follows to determine which instances are causing the problem:
SQL> SELECT INSTANCE_NAME, HOST_NAME FROM GV$INSTANCE 2> WHERE INST_ID <> (SELECT INSTANCE_NUMBER FROM V$INSTANCE); INSTANCE_NAME HOST_NAME ------------- --------- INST2 standby2
In the previous example, the identified instance must be manually shut down before the switchover can proceed. You can connect to the identified instance from your instance and issue the SHUTDOWN statement remotely, for example:
SQL> CONNECT SYS/CHANGE_ON_INSTALL@standby2 AS SYSDBA SQL> SHUTDOWN; SQL> EXIT
If you configured Data Guard to support a primary database in a Real Application Clusters environment and the primary database is running in maximum protection mode, a network outage between the primary database and all of its physical standby databases will disable the primary database until the network connection is restored. The maximum protection mode dictates that if the last participating physical standby database becomes unavailable, processing halts on the primary database.
If you expect the network to be down for an extended period of time, consider changing the primary database to run in either the maximum availability or the maximum performance mode until network connectivity is restored. If you change the primary database to maximum availability mode, it is possible for there to be a lag between the primary and standby databases, but you gain the ability to use the primary database until the network problem is resolved.
If you choose to change the primary database to the maximum availability mode, it is important to use the following procedures to prevent damage to your data.
Perform the following steps if the network goes down, and you want to change the protection mode for the Real Application Clusters configuration:
Later, when the network comes back up, perform the following steps to revert to the maximum protection mode:
|
 Copyright © 1998, 2002 Oracle Corporation. All Rights Reserved. |
|

