Release 2 (9.2)
Part Number A96595-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Data Cartridge Developer's Guide Release 2 (9.2) Part Number A96595-01 |
|
Oracle provides a number of pre-defined aggregate functions such as MAX, MIN, SUM for performing operations on a set of rows. These pre-defined aggregate functions can be used only with scalar data. However, you can define your own custom implementations of these functions, or define entirely new aggregate functions, to use with complex data--for example, with multimedia data stored using object types, opaque types, and LOBs.
User-defined aggregate functions are used in SQL DML statements just like Oracle's own built-in aggregates. Once such functions are registered with the server, Oracle simply invokes the aggregation routines that you supplied instead of the native ones.
User-defined aggregates can be used with scalar data too. For example, it may be worthwhile to implement special aggregate functions for working with complex statistical data associated with financial or scientific applications.
User-defined aggregates are a feature of the Extensibility Framework. You implement them using ODCIAggregate interface routines. This chapter explains how.
This chapter contains these major sections:
| See Also:
Chapter 19, "Reference: User-Defined Aggregates Interface" for a description of the |
You create a user-defined aggregate function by implementing a set of routines collectively referred to as the ODCIAggregate routines. You implement the routines as methods within an object type, so the implementation can be in any Oracle-supported language for type methods, such as PL/SQL, C/C++ or Java. When the object type is defined and the routines are implemented in the type body, you use the CREATE FUNCTION statement to create the aggregate function.
Each of the four ODCIAggregate routines required to define a user-defined aggregate function codifies one of the internal operations that any aggregate function performs, namely:
For example, consider the aggregate function AVG() in the following statement:
SELECT AVG(T.Sales) FROM AnnualSales T GROUP BY T.State;
To perform its computation, the aggregate function AVG() goes through steps like these:
runningSum = 0; runningCount = 0;
runningSum += inputval; runningCount++;
return (runningSum/runningCount);
In this example, the Initialize step initializes the aggregation context--the rows over which aggregation is performed. The Iterate step updates the context, and the Terminate step uses the context to return the resultant aggregate value.
If AVG() were a user-defined function, the object type that embodies it would implement a method for a corresponding ODCIAggregate routine for each of these steps. The variables runningSum and runningCount, which determine the state of the aggregation in the example, would be attributes of that object type.
Sometimes a fourth step may be necessary to merge two aggregation contexts and create a new context:
runningSum = runningSum1 + runningSum2; runningCount = runningCount1 + runningCount2
This operation combines the results of aggregation over subsets in order to obtain the aggregate over the entire set. This extra step can be required during either serial or parallel evaluation of an aggregate. If needed, it is performed before the Terminate step.
The four ODCIAggregate routines corresponding to the preceding steps are:
The process of creating a user-defined aggregate function has two steps. Here is an overview of the steps, using the SpatialUnion() aggregate function defined by the spatial cartridge. The function computes the bounding geometry over a set of input geometries.
The ODCIAggregate routines are implemented as methods within an object type SpatialUnionRoutines. The actual implementation could be in any Oracle-supported language for type methods, such as PL/SQL, C/C++ or Java.
CREATE TYPE SpatialUnionRoutines( STATIC FUNCTION ODCIAggregateInitialize( ... ) ..., MEMBER FUNCTION ODCIAggregateIterate(...) ... , MEMBER FUNCTION ODCIAggregateMerge(...) ..., MEMBER FUNCTION ODCIAggregateTerminate(...) ); CREATE TYPE BODY SpatialUnionRoutines IS ... END;
This step creates the SpatialUnion() aggregate function by specifying its signature and the object type that implements the ODCIAggregate interface.
CREATE FUNCTION SpatialUnion(x Geometry) RETURN Geometry AGGREGATE USING SpatialUnionRoutines;
User-defined aggregates can be used just like built-in aggregate functions in SQL DML and query statements. They can appear in the SELECT list, ORDER BY clause, or as part of the predicate in the HAVING clause.
For example, the following query can be used to compute state boundaries by aggregating the geometries of all counties belonging to the same state:
SELECT SpatialUnion(geometry) FROM counties GROUP BY state
User-defined aggregates can be used in the HAVING clause to eliminate groups from the output based on the results of the aggregate function. In the following example, MyUDAG() is a user-defined aggregate:
SELECT groupcol, MyUDAG(col) FROM tab GROUP BY groupcol HAVING MyUDAG(col) > 100 ORDER BY MyUDAG(col);
User-defined aggregates can take DISTINCT or ALL (default) options on the input parameter. DISTINCT causes duplicate values to be ignored while computing an aggregate.
The SELECT statement containing a user-defined aggregate can also include GROUP BY extensions such as ROLLUP, CUBE and grouping sets. For example:
SELECT ..., MyUDAG(col) FROM tab GROUP BY ROLLUP(gcol1, gcol2);
The ODCIAggregateMerge interface is invoked to compute superaggregate values in such rollup operations.
| See Also:
Oracle9i Data Warehousing Guide for information about |
Like built-in aggregate functions, user-defined aggregates can be evaluated in parallel. However, the aggregate function must be declared to be parallel-enabled, as follows:
CREATE FUNCTION MyUDAG(...) RETURN ... PARALLEL_ENABLE AGGREGATE USING MyAggrRoutines;
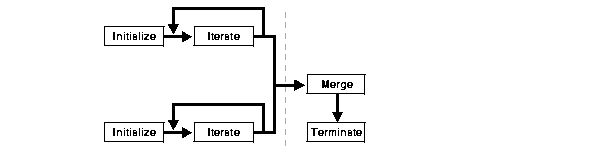
The aggregation contexts generated by aggregating subsets of the rows within the parallel slaves are sent back to the next parallel step (either the query coordinator or the next slave set), which then invokes the Merge routine to merge the aggregation contexts and, finally, invokes the Terminate routine to obtain the aggregate value.
The sequence of calls in this scenario is as follows:
When the implementation type methods are implemented in an external language (such as C or Java), the aggregation context must be passed back and forth between the Oracle server process and the external function's language environment each time an implementation type method is called.
Passing a large aggregation context can have an adverse effect on performance. To avoid this, you can store the aggregation context in external memory, allocated in the external function's execution environment, and pass just a reference or key to the context instead of the context itself. The key should be stored in the implementation type instance (the self); you can then pass the key between the Oracle server and the external function.
Passing a key to the context instead of the context itself keeps the implementation type instance small so that it can be transferred quickly. Another advantage of this strategy is that the memory used to hold the aggregation context is allocated in the function's execution environment (for example, extproc), and not in the Oracle server.
Usually you should allocate the memory to hold the aggregation context in ODCIAggregateInitialize and store the reference to it in the implementation type instance. In subsequent calls, the external memory and the aggregation context that it contains can be accessed using the reference. The external memory should usually be freed in ODCIAggregateTerminate. ODCIAggregateMerge should free the external memory used to store the merged context (the second argument of ODCIAggregateMerge) after the merge is done.
With parallel execution of queries with user-defined aggregates, the entire aggregation context comprising all partial aggregates computed by slave processes must sometimes be transmitted to another slave or to the master process. You can implement the optional routine ODCIAggregateWrapContext to collect all the partial aggregates. If a user-defined aggregate is being evaluated in parallel, and ODCIAggregateWrapContext is defined, Oracle invokes the routine to copy all external context references into the implementation type instance.
The ODCIAggregateWrapContext method should copy the aggregation context from external memory to the implementation type instance and free the external memory. To support ODCIAggregateWrapContext, the implementation type must contain attributes to hold the aggregation context and another attribute to hold the key that identifies the external memory.
When the aggregation context is stored externally, the key attribute of the implementation type should contain the reference identifying the external memory, and the remaining attributes of the implementation type should be NULL. After ODCIAggregateWrapContext is called, the key attribute should be NULL, and the other attributes should hold the actual aggregation context.
The following example shows an aggregation context type that contains references to external memory and is also able to store the entire context when needed.
CREATE TYPE MyAggrRoutines AS OBJECT ( -- The 4 byte key that is used to look up the external context. -- When NULL, it implies that the entire context value is self-contained: -- the context value is held by the rest of the attributes in this object. key RAW(4), -- The following attributes correspond to the actual aggregation context. If -- the key value is non-null, these attributes are all NULL. However, when -- the context object is self-contained (for example, after a call to -- ODCIAggregateWrapContext), these attributes hold the context value. ctxval GeometrySet, ctxval2 ... );
Each of the implementation type's member methods should begin by checking whether the context is inline (contained in the implementation type instance) or in external memory. If the context is inline (for example, because it was sent from another parallel slave), it should be copied to external memory so that it can be passed by reference.
Implementation of ODCIAggregateWrapContext is optional. It should be implemented only when external memory is used to hold the aggregation context, and the user-defined aggregate is evaluated in parallel (that is, declared as PARALLEL_ENABLE). If the user-defined aggregate is not evaluated in parallel, ODCIAggregateWrapContext is not needed.
If the ODCIAggregateWrapContext method is not defined, Oracle assumes that the aggregation context is not stored externally and does not try to call the method.
When user-defined aggregates are used as analytic functions, the aggregation context can be reused from one window to the next. In these cases, the flag argument of the ODCIAggregateTerminate function has its ODCI_AGGREGATE_REUSE_CTX bit set to indicate that the external memory holding the aggregation context should not be freed. Also, the ODCIAggregateInitialize method is passed the implementation type instance of the previous window, so you can access and just re-initialize the external memory allocated previously instead of having to allocate memory again.
ODCIAggregateInitialize - If the implementation type instance passed is not null, use the previously allocated external memory (instead of allocating external memory) and reinitialize the aggregation context.ODCIAggregateTerminate - Free external memory only if the bit ODCI_AGGREGATE_REUSE_CTX of the flag argument is not set.ODCIAggregateMerge - Free external memory associated with the merged aggregation context.ODCIAggregateWrapContext - Copy the aggregation context from the external memory into the implementation type instance and free the external memory.A materialized view definition can contain user-defined aggregates as well as built-in aggregate operators. For example :
CREATE MATERIALIZED VIEW MyMV AS SELECT gcols, MyUDAG(c1) FROM tab GROUP BY (gcols);
For the materialized view to be enabled for query rewrite, the user-defined aggregates in the materialized view must be declared as DETERMINISTIC. For example:
CREATE FUNCTION MyUDAG(x NUMBER) RETURN NUMBER DETERMINISTIC AGGREGATE USING MyImplType; CREATE MATERIALIZED VIEW MyMV ENABLE QUERY REWRITE AS SELECT gcols, MyUDAG(c1) FROM tab GROUP BY (gcols);
If a user-defined aggregate is dropped or re-created, all dependent materialized views are marked invalid.
| See Also:
Oracle9i Data Warehousing Guide for information about materialized views |
Analytic functions (formerly called window, or windowing functions) enable you to compute various cumulative, moving, and centered aggregates over a set of rows called a window. The syntax provides for defining the window. For each row in a table, analytic functions return a value computed on the other rows contained in the given row's window. These functions provide access to more than one row of a table without a self-join.
User-defined aggregates can be used as analytic functions. For example:
SELECT Account_number, Trans_date, Trans_amount, MyAVG (Trans_amount) OVER (PARTITION BY Account_number ORDER BY Trans_date RANGE INTERVAL '7' DAY PRECEDING) AS mavg_7day FROM Ledger;
When a user-defined aggregate is used as an analytic function, the aggregate is calculated for each row's corresponding window. Generally, each successive window contains largely the same set of rows, such that the new aggregation context (the new window) differs by only a few rows from the old aggregation context (the previous window). You can implement an optional routine--ODCIAggregateDelete--that enables Oracle to more efficiently reuse the aggregation context. If the aggregation context cannot be reused, all the rows it contains must be reiterated to rebuild it.
To reuse the aggregation context, any new rows that were not in the old context must be iterated over to add them, and any rows from the old context that do not belong in the new context must be removed.
The optional routine ODCIAggregateDelete removes from the aggregation context rows from the previous context that are not in the new (current) window. Oracle calls this routine for each row that must be removed. For each row that must be added, Oracle calls ODCIAggregateIterate.
If the new aggregation context is a superset of the old one--in other words, contains all the rows from the old context, such that none need to be deleted--then Oracle reuses the old context even if ODCIAggregateDelete is not implemented.
See Also:
|
This example illustrates creating a simple user-defined aggregate function SecondMax() that returns the second-largest value in a set of numbers.
SecondMaxImpl to contain the ODCIAggregate routines.
create type SecondMaxImpl as object ( max NUMBER, -- highest value seen so far secmax NUMBER, -- second highest value seen so far static function ODCIAggregateInitialize(sctx IN OUT SecondMaxImpl) return number, member function ODCIAggregateIterate(self IN OUT SecondMaxImpl, value IN number) return number, member function ODCIAggregateTerminate(self IN SecondMaxImpl, returnValue OUT number, flags IN number) return number, member function ODCIAggregateMerge(self IN OUT SecondMaxImpl, ctx2 IN SecondMaxImpl) return number ); /
SecondMaxImpl.
create or replace type body SecondMaxImpl is static function ODCIAggregateInitialize(sctx IN OUT SecondMaxImpl) return number is begin sctx := SecondMaxImpl(0, 0); return ODCIConst.Success; end; member function ODCIAggregateIterate(self IN OUT SecondMaxImpl, value IN number) return number is begin if value > self.max then self.secmax := self.max; self.max := value; elsif value > self.secmax then self.secmax := value; end if; return ODCIConst.Success; end; member function ODCIAggregateTerminate(self IN SecondMaxImpl, returnValue OUT number, flags IN number) return number is begin returnValue := self.secmax; return ODCIConst.Success; end; member function ODCIAggregateMerge(self IN OUT SecondMaxImpl, ctx2 IN SecondMaxImpl) return number is begin if ctx2.max > self.max then if ctx2.secmax > self.secmax then self.secmax := ctx2.secmax; else self.secmax := self.max; end if; self.max := ctx2.max; elsif ctx2.max > self.secmax then self.secmax := ctx2.max; end if; return ODCIConst.Success; end; end; /
CREATE FUNCTION SecondMax (input NUMBER) RETURN NUMBER PARALLEL_ENABLE AGGREGATE USING SecondMaxImpl;
SELECT SecondMax(salary), department_id FROM employees GROUP BY department_id HAVING SecondMax(salary) > 9000;
|
 Copyright © 1996, 2002 Oracle Corporation. All Rights Reserved. |
|

