The
following documentation discusses developing with the MN10200 and MN10300
Matsushita processors.
Matsushita
MN10200 development
The following
documentation discusses developing with the GNUPro tools for the MN10200
targets.
Compiler options
for MN10200
For a list of
available generic compiler options, see GNU
CC command options and Option
summary for GCC in Using GNU CC in GNUPro Compiler Tools.
There are no MN10200-specific command-line compiler options.
Preprocessor
symbols for MN10200
By default,
the compiler defines the preprocessor symbols with the __MN10200__
and __mn10200__ names.
MN10200-specific attributes
There are no
MN10200-specific attributes. See Declaring
attributes of functions and Specifying
attributes of variables in Using GNU CC in GNUPro Compiler
Tools for more information regarding extensions to the C language
family.
For a list of
available generic compiler options, see GNU
CC command options in Using GNU CC in GNUPro Compiler
Tools.
ABI
summary for MN10200
The following
documentation discusses the MN10200 Application Binary Interface (ABI),
including specifications such as executable format, calling conventions,
and chip-specific requirements.
Data type and alignment for
MN10200
The following
table shows the data type sizes.
Data
type sizes for the MN10200
The stack is kept
2-byte aligned. Structures and unions have the same alignment as their
most strictly aligned component.
CPU register allocation
for MN10200
The compiler
allocates registers in the following order: d0, d1, a0,
d2,
d3,
a1,
a2 .
a3 is
the stack pointer and is not an allocable register.
a2 is
the frame pointer in functions which need a frame pointer; otherwise it
is an allocable register.
CPU
register allocation for MN10200
The compiler does
not generate code that uses ccr.
The special-purpose
register, mdr, is only used for integer division and modulo operations.
Switches for MN10200
There are no
MN10200 specific switches.
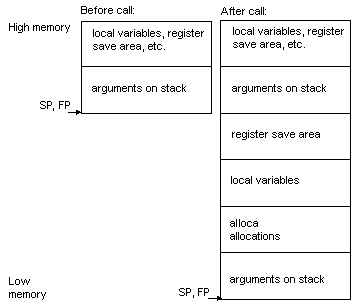
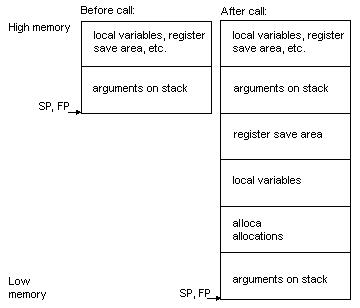
The
stack frame for MN10200
The stack frame
has the following attributes for the MN10200.
-
The stack grows downwards from
high addresses to low addresses.
-
A leaf function need not allocate
a stack frame if it does not need one.
-
A frame pointer need not be allocated.
-
The stack pointer shall always
be aligned to 2 byte boundaries.
For stack frame
information for the MN10200, see MN10200
stack frames for functions that take a fixed number of arguments for
functions taking a fixed number of arguments and see MN10200
stack frames for functions that take a variable number of arguments
for functions taking a varaible number of arguments.
Stack frames
for functions taking a variable number of arguments use a frame pointer
(FP) that points to the same location
as the stack pointer (SP).
Argument
passing for the MN10200
d0 and
d1
are
used for passing the first two argument words, any additional ar gument
words are passed on the stack.
Any argument,
more than 8 bytes in size, is passed by invisible reference. The callee
is responsible for copying the argument if the callee modifies the argument.
Function
return values for the MN10200
a0 is
used to return pointer values.
d0 and d1
are
u sed for returning other scalars and structures less than or equal to
8 bytes in length.
If a function
returns a structure that is greater than 8 bytes in length, then the caller
is responsible for passing in a pointer to the callee specifying a location
for the callee to store the return value. This pointer is passed as the
first argument word before any of the function's declared parameters.
Assembler
features for the MN10200
For a list of
available generic assembler options, see Command-line
options in Using as in GNUPro Utilities.
There are no MN10200 specific assembler command-line options.
The MN10200
syntax is based on the syntax in Matsushitas MN10200 Architecture Manual.
The assembler
does not support user defined instructionsnor does it support synthesized
instructions (pseudo instructions corresponding to two or more actual machine
instructions).
The MN10200
assembler supports ; (semi-colon) and # (pound);
both characters are line comment characters when used in column zero. The
semi-colon may also be used to start a comment anywhere within a line.
The following
register names are supported for the MN10200: d0, d1,
d2,
d3,
a0,
a1, a2, a3,
mdr,
ccr .
The following
addressing modes work for the MN10200.
-
Register direct:
Dm/Dn
Am/An
-
Immediate value:
imm8/regs
imm16
imm24
-
Register indirect:
(Am)/(An)
-
Register indirect with displacement
:
(d8,Am)/(d8,An) (d8 is
sign extended)
(d16,Am)/(d16,An) (d16 is sign extended)
(d24,Am)/(d24,An)
(d8,pc) (d8 is signed extended)
(d16,pc) (d16 is signed extended)
(d24,pc)
-
Absolute:
(abs16) (abs16 is zero extended)
(abs24)
-
Register indirect with index:
(Di,Am)/(Di,An)
m,
n,
and i subscripts indicate, respectively: source, destination and
index. The values of m, n and i are from 0 to
3.
For detailed
information, see MN102000 Series Linear Addressing Version Instruction
Manual.
Although the
MN10200 has no hardware floating point, the .float and .double
directives generate IEEE-format floating-point values for compatibility
with other development tools.
For detailed
information on the MN10200 machine instruction set, see MN10200 Series
Instruction Manual. The GNU assembler implements all the standard
MN10200 opcodes.
The assembler
does not support user defined instructionsnor does it support synthesized
instructions (pseudo instructions, corresponding to two or more actual
machine instructions).
MN10200-specific assembler
error messages
The following
warnings may appear for the MN10200.
Error:
Unrecognized opcode
An instruction is misspelled or there is a syntax
error somewhere.
Warning:
operand out of range
An immediate value was specified that is too
large for the instruction
Linker
features for MN10200
The following
documentation describes MN10200-specific features of the GNUPro linker.
For a list of available generic linker options, see Linker
scripts in Using ld in GNUPro Utilities.
The GNU linker
uses a linker script to determine how to process each section in an object
file, and how to lay out the executable. The linker script is a declarative
program consisting of a number of directives. For instance, the ENTRY()
directive specifies the symbol in the executable that will be the executable's
entry point. For the MN10200 tools, there are two linker scripts, one used
when compiling for the simulator and one used when compiling for the evaluation
board.
-relax
is a special option for the MN10200 that enables the optimization linker
pass to shorten branches.
The following
example is sim.ld, the linker script for the simulator.
/* Linker script for the MN10200 simulator. */
OUTPUT_FORMAT("elf32-mn10200", "elf32-mn10200",
"elf32-mn10200")
OUTPUT_ARCH(mn10200)
ENTRY(_start)
GROUP(-lc -leval -lgcc)
SEARCH_DIR(.);
/* Do we need any of these for elf?
__DYNAMIC = 0; */
SECTIONS
{
/* Read-only sections, merged into text segment: */
. = 0x0;
.interp : { *(.interp) }
.hash : { *(.hash)}
.dynsym : { *(.dynsym)}
.dynstr : { *(.dynstr)}
.gnu.version : { *(.gnu.version)}
.gnu.version_d : { *(.gnu.version_d)}
.gnu.version_r : { *(.gnu.version_r)}
.rel.text :
{ *(.rel.text) *(.rel.gnu.linkonce.t*) }
.rela.text :
{ *(.rela.text) *(.rela.gnu.linkonce.t*) }
.rel.data :
{ *(.rel.data) *(.rel.gnu.linkonce.d*) }
.rela.data :
{ *(.rela.data) *(.rela.gnu.linkonce.d*) }
.rel.rodata :
{ *(.rel.rodata) *(.rel.gnu.linkonce.r*) }
.rela.rodata :
{ *(.rela.rodata) *(.rela.gnu.linkonce.r*) }
.rel.got : { *(.rel.got)}
.rela.got : { *(.rela.got)}
.rel.ctors : { *(.rel.ctors)}
.rela.ctors : { *(.rela.ctors)}
.rel.dtors : { *(.rel.dtors)}
.rela.dtors : { *(.rela.dtors)}
.rel.init : { *(.rel.init)}
.rela.init : { *(.rela.init)}
.rel.fini : { *(.rel.fini)}
.rela.fini : { *(.rela.fini)}
.rel.bss : { *(.rel.bss)}
.rela.bss : { *(.rela.bss)}
.rel.plt : { *(.rel.plt)}
.rela.plt : { *(.rela.plt)}
.init : { *(.init)} =0
.plt : { *(.plt)}
.text :
{
*(.text)
*(.stub)
/* .gnu.warning sections are handled specially by elf32.em. */
*(.gnu.warning)
*(.gnu.linkonce.t*)
} =0
_etext = .;
PROVIDE (etext = .);
.fini : { *(.fini) } =0
.rodata : { *(.rodata) *(.gnu.linkonce.r*) }
.rodata1 : { *(.rodata1) }
/* Adjust the address for the data segment. We want to adjust up to
the same address within the page on the next page up. */
. = ALIGN(256) + (. & (256 - 1));
.data :
{
*(.data)
*(.gnu.linkonce.d*)
CONSTRUCTORS
}
.data1 : { *(.data1) }
.ctors :
{
___ctors = .;
/* gcc uses crtbegin.o to find the start of the constructors, so
we make sure it is first. Because this is a wildcard, it
doesn't matter if the user does not actually link against
crtbegin.o; the linker won't look for a file to match a
wildcard. The wildcard also means that it doesn't matter which
directory crtbegin.o is in. */
*crtbegin.o(.ctors)
*(SORT(.ctors.*))
*(.ctors)
___ctors_end = .;
}
.dtors :
{
___dtors = .;
*crtbegin.o(.dtors)
*(SORT(.dtors.*))
*(.dtors)
___dtors_end = .;
}
.got : { *(.got.plt) *(.got) }
.dynamic : { *(.dynamic) }
/* We want the small data sections together, so single-instruction offsets
can access them all, and initialized data all before uninitialized, so
we can shorten the on-disk segment size. */
.sdata : { *(.sdata) }
_edata = .;
PROVIDE (edata = .);
__bss_start = .;
.sbss : { *(.sbss) *(.scommon) }
.bss :
{
*(.dynbss)
*(.bss)
*(COMMON)
}
. = ALIGN(32 / 8);
_end = . ;
PROVIDE (end = .);
/* Stabs debugging sections. */
.stab 0 : { *(.stab) }
.stabstr 0 : { *(.stabstr) }
.stab.excl 0 : { *(.stab.excl) }
.stab.exclstr 0 : { *(.stab.exclstr) }
.stab.index 0 : { *(.stab.index) }
.stab.indexstr 0 : { *(.stab.indexstr) }
.comment 0 : { *(.comment) }
/* DWARF debug sections.
Symbols in the DWARF debugging sections are relative to the beginning
of the section so we begin them at 0. */
/* DWARF 1 */
.debug 0 : { *(.debug) }
.line 0 : { *(.line) }
/* GNU DWARF 1 extensions */
.debug_srcinfo 0 : { *(.debug_srcinfo) }
.debug_sfnames 0 : { *(.debug_sfnames) }
/* DWARF 1.1 and DWARF 2 */
.debug_aranges 0 : { *(.debug_aranges) }
.debug_pubnames 0 : { *(.debug_pubnames) }
/* DWARF 2 */
.debug_info 0 : { *(.debug_info) }
.debug_abbrev 0 : { *(.debug_abbrev) }
.debug_line 0 : { *(.debug_line) }
.debug_frame 0 : { *(.debug_frame) }
.debug_str 0 : { *(.debug_str) }
.debug_loc 0 : { *(.debug_loc) }
.debug_macinfo 0 : { *(.debug_macinfo) }
/* SGI/MIPS DWARF 2 extensions */
.debug_weaknames 0 : { *(.debug_weaknames) }
.debug_funcnames 0 : { *(.debug_funcnames) }
.debug_typenames 0 : { *(.debug_typenames) }
.debug_varnames 0 : { *(.debug_varnames) }
.stack 0x80000 : { _stack = .; *(.stack) }
/* These must appear regardless of . */
}
The following
example shows eval.ld, the linker script for the MN10200 evaluation
board.
/* Linker script for the MN10200 Evaluation Board.
It differs from the default linker script only in the
addresses assigned to text and stack sections.
*/
OUTPUT_FORMAT("elf32-mn10200", "elf32-mn10200",
"elf32-mn10200")
OUTPUT_ARCH(mn10200)
ENTRY(_start)
GROUP(-lc -leval -lgcc)
SEARCH_DIR(.);
/* Do we need any of these for elf?
__DYNAMIC = 0; */
SECTIONS
{
/* Read-only sections, merged into text segment: */
/* Start of RAM (leaving room for Cygmon data) */
. = 0x408000;
.interp : { *(.interp) }
.hash : { *(.hash)}
.dynsym : { *(.dynsym)}
.dynstr : { *(.dynstr)}
.gnu.version : { *(.gnu.version)}
.gnu.version_d : { *(.gnu.version_d)}
.gnu.version_r : { *(.gnu.version_r)}
.rel.text :
{ *(.rel.text) *(.rel.gnu.linkonce.t*) }
.rela.text :
{ *(.rela.text) *(.rela.gnu.linkonce.t*) }
.rel.data :
{ *(.rel.data) *(.rel.gnu.linkonce.d*) }
.rela.data :
{ *(.rela.data) *(.rela.gnu.linkonce.d*) }
.rel.rodata :
{ *(.rel.rodata) *(.rel.gnu.linkonce.r*) }
.rela.rodata :
{ *(.rela.rodata) *(.rela.gnu.linkonce.r*) }
.rel.got : { *(.rel.got)}
.rela.got : { *(.rela.got)}
.rel.ctors : { *(.rel.ctors)}
.rela.ctors : { *(.rela.ctors)}
.rel.dtors : { *(.rel.dtors)}
.rela.dtors : { *(.rela.dtors)}
.rel.init : { *(.rel.init)}
.rela.init : { *(.rela.init)}
.rel.fini : { *(.rel.fini)}
.rela.fini : { *(.rela.fini)}
.rel.bss : { *(.rel.bss)}
.rela.bss : { *(.rela.bss)}
.rel.plt : { *(.rel.plt)}
.rela.plt : { *(.rela.plt)}
.init : { *(.init)} =0
.plt : { *(.plt)}
.text :
{
*(.text)
*(.stub)
/* .gnu.warning sections are handled specially by elf32.em. */
*(.gnu.warning)
*(.gnu.linkonce.t*)
} =0
_etext = .;
PROVIDE (etext = .);
.fini : { *(.fini) } =0
.rodata : { *(.rodata) *(.gnu.linkonce.r*) }
.rodata1 : { *(.rodata1) }
/* Adjust the address for the data segment. We want to adjust up to
the same address within the page on the next page up. */
. = ALIGN(256) + (. & (256 - 1));
.data :
{
*(.data)
*(.gnu.linkonce.d*)
CONSTRUCTORS
}
.data1 : { *(.data1) }
.ctors :
{
___ctors = .;
/* gcc uses crtbegin.o to find the start of the constructors, so
we make sure it is first. Because this is a wildcard, it
doesn't matter if the user does not actually link against
crtbegin.o; the linker won't look for a file to match a
wildcard. The wildcard also means that it doesn't matter which
directory crtbegin.o is in. */
*crtbegin.o(.ctors)
*(SORT(.ctors.*))
*(.ctors)
___ctors_end = .;
}
.dtors :
{
___dtors = .;
*crtbegin.o(.dtors)
*(SORT(.dtors.*))
*(.dtors)
___dtors_end = .;
}
.got : { *(.got.plt) *(.got) }
.dynamic : { *(.dynamic) }
/* We want the small data sections together, so single-instruction offsets
can access them all, and initialized data all before uninitialized, so
we can shorten the on-disk segment size. */
.sdata : { *(.sdata) }
_edata = .;
PROVIDE (edata = .);
__bss_start = .;
.sbss : { *(.sbss) *(.scommon) }
.bss :
{
*(.dynbss)
*(.bss)
*(COMMON)
}
. = ALIGN(32 / 8);
_end = . ;
PROVIDE (end = .);
/* Stabs debugging sections. */
.stab 0 : { *(.stab) }
.stabstr 0 : { *(.stabstr) }
.stab.excl 0 : { *(.stab.excl) }
.stab.exclstr 0 : { *(.stab.exclstr) }
.stab.index 0 : { *(.stab.index) }
.stab.indexstr 0 : { *(.stab.indexstr) }
.comment 0 : { *(.comment) }
/* DWARF debug sections.
Symbols in the DWARF debugging sections are relative to the
beginning of the section so we begin them at 0. */
/* DWARF 1 */
.debug 0 : { *(.debug) }
.line 0 : { *(.line) }
/* GNU DWARF 1 extensions */
.debug_srcinfo 0 : { *(.debug_srcinfo) }
.debug_sfnames 0 : { *(.debug_sfnames) }
/* DWARF 1.1 and DWARF 2 */
.debug_aranges 0 : { *(.debug_aranges) }
.debug_pubnames 0 : { *(.debug_pubnames) }
/* DWARF 2 */
.debug_info 0 : { *(.debug_info) }
.debug_abbrev 0 : { *(.debug_abbrev) }
.debug_line 0 : { *(.debug_line) }
.debug_frame 0 : { *(.debug_frame) }
.debug_str 0 : { *(.debug_str) }
.debug_loc 0 : { *(.debug_loc) }
.debug_macinfo 0 : { *(.debug_macinfo) }
/* SGI/MIPS DWARF 2 extensions */
.debug_weaknames 0 : { *(.debug_weaknames) }
.debug_funcnames 0 : { *(.debug_funcnames) }
.debug_typenames 0 : { *(.debug_typenames) }
.debug_varnames 0 : { *(.debug_varnames) }
/* Top of RAM is 0x43ffff, but Cygmon uses the top 4K for its stack. */
.stack 0x43f000 : { _stack = .; *(.stack) }
/* These must appear regardless of . */
}
Debugger
issues for MN10200
There are two
ways for GDB to talk to an MN10200 target. Each target requires that the
program be compiled with atarget specific linker script.
-
Simulator
GDBs built-in software simulation of the MN10200 processor
allows the debugging of programs compiled for the MN10200 without requiring
any access to actual hardware. For this target, the sim.ld linker
script must be specified at compilation. To activate this mode in GDB,
use a target sim command. Then load the code into the simulator
by using the load command and debug it in the normal fashion.
-
Remote target board
For this target, the eval.ld linker script must
be specified at compilation. To connect to the target board in GDB, use
the target remote <devicename> command where
<devicename> will be a serial device such as /dev/ttya
for Unix, or com2 for Windows NT. Then, load the code onto the
target board by using a load command. After being downloaded,
the program executes.
When using the
remote target, GDB does not accept the run command. However, since
downloading the program has the side effect of setting the PC to the start
address, you can start your program by using a continue command.
For the available
generic debugger options, see Debugging
with GDB in GNUPro Debugging Tools. There are no
MN10200-specific debugger command-line options.
Simulator
issues for MN10200
The simulator
supports the following registers.
-
Volatile registers are d0,
d1,
a0,
a1.
-
Saved registers are d2,
d3,
a2,
a3.
-
Special purpose registers are
pc,
ccr,
mdr.
Memory is 256k
bytes starting at location 0. The stack starts at the highest memory address
and works downward. The heap starts at the lowest address after the text,
data and bss.
There are no
MN10200-specific simulator command-line options.
CygMon usage with MN10200
CygMon is a
ROM monitor designed to be portable across a large number of embedded systems.
Configuring
CygMon for MN10200
The following
documentation explains how to configure, build, and load CygMon ROM monitor
program under the Unix operating system.
The following
conventions have been used in this example configuration:
-
The Unix forward slash is the
directory delimiter in all path descriptions.
-
% is the Unix command
prompt.
-
source_dir represents
the complete path to the directory, which contains the source code. The
user can install the source code in any directory.
-
build_dir
represents the complete path to the user created build directory.
The following
steps show how to configure, build, and load CygMon ROM monitor program
under the Unix operating system.
1.
Create a
build directory and use the cd command to get to that directory.
% cd build_dir
2.
Configure
the toolchain normally.
% source_dir/configure ---target=mn10200-elf
3.
Now
use the following command to build a CygMON image in S-records that can
be downloaded to a PROM burner or emulator.
% make all-target-cygmon
The
S-record image will be in the following file.
build_dir/mn10200-elf/cygmon/mn10200/cygmon.sre
CygMon uses
the single serial port on the MN10200 evaluation board. The default settings
are 19200, n, 8, 1.
Building
programs with MN10200 for using CygMon
There is a special
linker script for use with CygMon. The following example shows a final
link command.
% mn10200-elf-gcc hello.o -Teval.ld -o hello
eval.ld
is
the linker script. The user program is given a program memory area starting
at the 0x408000 address, and a stack growing down from the 0x43f000
address. Space between the program memory and the stack pointer is used
for the heap.
The linker script
should be specified after all other object files and libraries, the simplest
way to ensure being to place it at the very end of the commandline.
Matsushita MN10300
development
The following
documentation discusses developing with the GNUPro tools for the MN10300
targets.
Compiler features for MN10300
The following
documentation describes MN10300-specific features of the GNUPro compiler.
MN10300-specific
command-line options
For a list of
available generic compiler options, see GNU
CC command options and Option
summary for GCC in Using
GNU CC in GNUPro Compiler Tools. In addition, the
following MN10300-specific command-line options are supported.
-mmult-bug
Generate code to work around bugs in the MN10300
multiply instruction. This is the default.
-mno-mult-bug
Do not generate code to work around bugs in the
MN10300 multiply instruction.
Preprocessor
symbols for MN10300
By default,
the compiler defines the __MN10300__ and __mn10300__
preprocessor symbols.
MN10300-specific
attributes
There are no
MN10300-specific attributes. See Declaring
attributes of functions and Specifying
attributes of variables in Using
GNU CC in GNUPro Compiler Tools for more information
regarding extensions to the C language family.
ABI
summary for MN10300
The following
documentation describes the MN10300 Application Binary Interface (ABI).
Data
types sizes and alignments for MN10300
Table
16 describes the size and alignment of the data types for the MN10300
processor.
Data
types, sizes and alignment for the MN10300
The following
issues are also pertinent to the MN10300 processor.
-
The stack is kept 4-byte aligned.
-
Structures and unions have the
same alignment as their most strictly aligned component.
Register
allocation for MN10300
The compiler
allocates registers in the following order: d0, d1, a0,
a1,
d2,
d3,
a2, a3.
Register
usage for MN10300
Table
17 describes register usage for the MN10300 processor.
Register
usage for MN10300
Switches
for MN10300
There are no
switches that effect the ABI or calling conventions. There are two switches
that control a particular aspect of code generation. See MN10300-specific
command-line options.
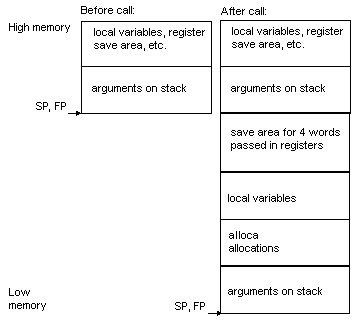
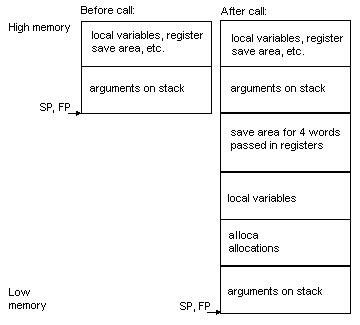
Stack
frame information for MN10300 targets
The following
documentation details stack frame usage for the MN10300 processor.
-
The stack grows downwards from
high addresses to low addresses.
-
A leaf function need not allocate
a stack frame if it does not need one.
-
A frame pointer need not be allocated.
-
The stack pointer shall always
be aligned to 4 byte boundaries.
For MN10300
stack frame information, see MN13000
stack frames for functions that take a fixed number of arguments for
functions taking a fixed number of arguments and see MN10300
stack frames for functions that take a variable number of arguments
for functions taking a variable number of arguments.
Stack frames
for functions taking a variable number of arguments use the following definitions.
The frame pointer (FP) points to the same
location as the stack pointer (SP).
Argument
passing for MN10300
d0
and d1 are used for passing the first two argument words, any
additional argument words are passed on the stack.
Any argument,
more than 8 bytes in size, is passed by invisible reference. The callee
is responsible for copying the argument if the callee modifies the argument.
Function
return values for MN10300
a0
is used to return pointer values. d0 and d1 are used
for returning other scalars and structures less than or equal to 8 bytes
in length.
If a function
returns a structure that is greater than 8 bytes in length, then the caller
is responsible for passing in a pointer to the callee which specifies a
location for the callee to store the return value. This pointer is passed
as the first argument word before any of the function's declared parameters.
Assembler
features for MN10300
The following
documentation describes MN10300-specific features of the GNUPro assembler.
MN10300
command-line assembler options
For a list of
available generic assembler options, see Command-line
options in Usingasin
GNUPro
Utilities. There are no MN10300 specific assembler command-line
options.
Syntax
for MN10300
The MN10300
syntax is based on the syntax in Matsushitas MN10300 Architecture
Manual.
The assembler
does not support user defined instructions nor does it support synthesized
instructions (pseudo instructions, which correspond to two or more actual
machine instructions).
Special
characters for MN10300
The MN10300
assembler supports ; (semi-colon) and # (pound).
Both characters are line comment characters when used in column zero. The
semi-colon may also be used to start a comment anywhere within a line.
Register
names for MN10300
The following
register names are supported for the MN10300: d0, d1,
d2,
d3,
a0,
a1, a2, a3,
sp,
mdr,
ccr,
lir, and lar.
Addressing
modes for MN10300
See Table
18 for the MN10300 assembler addressing modes.
|
|
|
|
|
|
|
|
|
imm48 |
|
|
|
|
|
|
|
|
| Register indirect |
|
| (Am)/(An) |
|
| Register indirect with
displacement |
|
| (d8, Am)/(d8, An) |
d8 is sign extended |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Register
indirect with index
|
|
|
m, n,
and iare subscripts that indicate source, destination and index,
respectively. m, nand ihave values from 0 to
3.
For detailed information,
see MN10300 Series Instruction Manual.
Floating
point for MN10300
Although the
MN10300 has no hardware floating point, the .float and .double
directives generate IEEE-format floating-point values for compatibility
with other development tools.
Opcodes
for MN10300
For detailed
information on the MN10300 machine instruction set, see MN10300 Series
Instruction Manual. The GNU assembler implements all the standard
MN10300 opcodes.
Synthetic
instructions for MN10300
The assembler
does not support user defined instructions nor does it support synthesized
instructions (pseudo instructions, which correspond to two or more actual
machine instructions).
MN10300-specific
assembler error messages
The following
error messages may happen for the MN10300.
Error: Unrecognized opcode
This instruction is misspelled or there is a
syntax error somewhere.
Warning: operand out of
range
An immediate value was specified that is too
large for the instruction.
Linker
features for the MN10300
The following
documentation describes MN10300-specific features of the GNUPro linker.
MN10300-specific
linker options
For a list of
available generic linker options, see Linker
scripts in Using ldin
GNUPro Utilities. In addition, the following MN10300-specific
command-line option is supported.
-relax
Enables the optimization linker pass to shorten
branches.
Linker
script for the MN10300
The GNU linker
uses a linker script to determine how to process each section in an object
file, and how to lay out the executable. The linker script is a declarative
program consisting of a number of directives. For instance, the ENTRY()
directive specifies the symbol in the executable that will be the executable's
entry point. For a complete description of the linker script, see Linker
scripts in Using ldin
GNUPro Utilities. For the MN10300 tools, there are two linker
scripts, one to be used when compiling for the simulator
and one to be used when compiling for the evaluation board.
This
is the sim.ld linker script for the simulator.
/* Linker script for the MN10300 simulator.
*/
OUTPUT_FORMAT("elf32-mn10300", "elf32-mn10300",
"elf32-mn10300")
OUTPUT_ARCH(mn10300)
ENTRY(_start)
GROUP(-lc -leval -lgcc)
SEARCH_DIR(/usr/local/mn10300-elf/lib);
/* Do we need any of these for elf?
__DYNAMIC = 0; */
SECTIONS
{
/* Read-only sections, merged into text segment: */
/* Start of RAM (leaving room for Cygmon data) */
. = 0;
.interp : { *(.interp) }
.hash : { *(.hash)}
.dynsym : { *(.dynsym)}
.dynstr : { *(.dynstr)}
.gnu.version : { *(.gnu.version)}
.gnu.version_d : { *(.gnu.version_d)}
.gnu.version_r : { *(.gnu.version_r)}
.rel.text :
{ *(.rel.text) *(.rel.gnu.linkonce.t*) }
.rela.text :
{ *(.rela.text) *(.rela.gnu.linkonce.t*) }
.rel.data :
{ *(.rel.data) *(.rel.gnu.linkonce.d*) }
.rela.data :
{ *(.rela.data) *(.rela.gnu.linkonce.d*) }
.rel.rodata :
{ *(.rel.rodata) *(.rel.gnu.linkonce.r*) }
.rela.rodata :
{ *(.rela.rodata) *(.rela.gnu.linkonce.r*) }
.rel.got : { *(.rel.got)}
.rela.got : { *(.rela.got)}
.rel.ctors : { *(.rel.ctors)}
.rela.ctors : { *(.rela.ctors)}
.rel.dtors : { *(.rel.dtors)}
.rela.dtors : { *(.rela.dtors)}
.rel.init : { *(.rel.init)}
.rela.init : { *(.rela.init)}
.rel.fini : { *(.rel.fini)}
.rela.fini : { *(.rela.fini)}
.rel.bss : { *(.rel.bss)}
.rela.bss : { *(.rela.bss)}
.rel.plt : { *(.rel.plt)}
.rela.plt : { *(.rela.plt)}
.init : { *(.init)} =0
.plt : { *(.plt)}
.text :
{
*(.text)
/* .gnu.warning sections are handled specially by elf32.em. */
*(.gnu.warning)
*(.gnu.linkonce.t*)
*(.gcc_except_table)
} =0
_etext = .;
PROVIDE (etext = .);
.fini : { *(.fini) } =0
.rodata : { *(.rodata) *(.gnu.linkonce.r*) }
.rodata1 : { *(.rodata1) }
/* Adjust the address for the data segment. We want to adjust up to
the same address within the page on the next page up. */
. = ALIGN(256) + (ALIGN(8) & (256 - 1));
.data :
{
*(.data)
*(.gnu.linkonce.d*)
CONSTRUCTORS
}
.data1 : { *(.data1) }
.ctors :
{
___ctors = .;
*(.ctors)
___ctors_end = .;
}
.dtors :
{
___dtors = .;
*(.dtors)
___dtors_end = .;
}
.got : { *(.got.plt) *(.got) }
.dynamic : { *(.dynamic) }
/* We want the small data sections together, so single-instruction offsets
can access them all, and initialized data all before uninitialized, so
we can shorten the on-disk segment size. */
.sdata : { *(.sdata) }
_edata = .;
PROVIDE (edata = .);
__bss_start = .;
.sbss : { *(.sbss) *(.scommon) }
.bss :
{
*(.dynbss)
*(.bss)
*(COMMON)
}
_end = . ;
PROVIDE (end = .);
/* Stabs debugging sections. */
.stab 0 : { *(.stab) }
.stabstr 0 : { *(.stabstr) }
.stab.excl 0 : { *(.stab.excl) }
.stab.exclstr 0 : { *(.stab.exclstr) }
.stab.index 0 : { *(.stab.index) }
.stab.indexstr 0 : { *(.stab.indexstr) }
.comment 0 : { *(.comment) }
/* DWARF debug sections.
Symbols in the DWARF debugging sections are relative to the beginning
of the section so we begin them at 0. */
/* DWARF 1 */
.debug 0 : { *(.debug) }
.line 0 : { *(.line) }
/* GNU DWARF 1 extensions */
.debug_srcinfo 0 : { *(.debug_srcinfo) }
.debug_sfnames 0 : { *(.debug_sfnames) }
/* DWARF 1.1 and DWARF 2 */
.debug_aranges 0 : { *(.debug_aranges) }
.debug_pubnames 0 : { *(.debug_pubnames) }
/* DWARF 2 */
.debug_info 0 : { *(.debug_info) }
.debug_abbrev 0 : { *(.debug_abbrev) }
.debug_line 0 : { *(.debug_line) }
.debug_frame 0 : { *(.debug_frame) }
.debug_str 0 : { *(.debug_str) }
.debug_loc 0 : { *(.debug_loc) }
.debug_macinfo 0 : { *(.debug_macinfo) }
/* SGI/MIPS DWARF 2 extensions */
.debug_weaknames 0 : { *(.debug_weaknames) }
.debug_funcnames 0 : { *(.debug_funcnames) }
.debug_typenames 0 : { *(.debug_typenames) }
.debug_varnames 0 : { *(.debug_varnames) }
.stack 0x80000 : { _stack = .; *(.stack) }
/* These must appear regardless of . */
}
This
is the eval.ld linker script for the MN10300 evaluation board.
/* Linker script for the MN10300 Series Evaluation Board.
It differs from the default linker script only in the
addresses assigned to text and stack sections.
*/
OUTPUT_FORMAT("elf32-mn10300", "elf32-mn10300",
"elf32-mn10300")
OUTPUT_ARCH(mn10300)
ENTRY(_start)
GROUP(-lc -leval -lgcc)
SEARCH_DIR(/usr/local/mn10300-elf/lib);
/* Do we need any of these for elf?
__DYNAMIC = 0; */
SECTIONS
{
/* Read-only sections, merged into text segment: */
/* Start of RAM (leaving room for Cygmon data) */
. = 0x48008000;
.interp : { *(.interp) }
.hash : { *(.hash)}
.dynsym : { *(.dynsym)}
.dynstr : { *(.dynstr)}
.gnu.version : { *(.gnu.version)}
.gnu.version_d : { *(.gnu.version_d)}
.gnu.version_r : { *(.gnu.version_r)}
.rel.text :
{ *(.rel.text) *(.rel.gnu.linkonce.t*) }
.rela.text :
{ *(.rela.text) *(.rela.gnu.linkonce.t*) }
.rel.data :
{ *(.rel.data) *(.rel.gnu.linkonce.d*) }
.rela.data :
{ *(.rela.data) *(.rela.gnu.linkonce.d*) }
.rel.rodata :
{ *(.rel.rodata) *(.rel.gnu.linkonce.r*) }
.rela.rodata :
{ *(.rela.rodata) *(.rela.gnu.linkonce.r*) }
.rel.got : { *(.rel.got)}
.rela.got : { *(.rela.got)}
.rel.ctors : { *(.rel.ctors)}
.rela.ctors : { *(.rela.ctors)}
.rel.dtors : { *(.rel.dtors)}
.rela.dtors : { *(.rela.dtors)}
.rel.init : { *(.rel.init)}
.rela.init : { *(.rela.init)}
.rel.fini : { *(.rel.fini)}
.rela.fini : { *(.rela.fini)}
.rel.bss : { *(.rel.bss)}
.rela.bss : { *(.rela.bss)}
.rel.plt : { *(.rel.plt)}
.rela.plt : { *(.rela.plt)}
.init : { *(.init)} =0
.plt : { *(.plt)}
.text :
{
*(.text)
/* .gnu.warning sections are handled specially by elf32.em. */
*(.gnu.warning)
*(.gnu.linkonce.t*)
*(.gcc_except_table)
} =0
_etext = .;
PROVIDE (etext = .);
.fini : { *(.fini) } =0
.rodata : { *(.rodata) *(.gnu.linkonce.r*) }
.rodata1 : { *(.rodata1) }
/* Adjust the address for the data segment. We want to adjust up to
the same address within the page on the next page up. */
. = ALIGN(256) + (ALIGN(8) & (256 - 1));
.data :
{
*(.data)
*(.gnu.linkonce.d*)
CONSTRUCTORS
}
.data1 : { *(.data1) }
.ctors :
{
___ctors = .;
*(.ctors)
___ctors_end = .;
}
.dtors :
{
___dtors = .;
*(.dtors)
___dtors_end = .;
}
.got : { *(.got.plt) *(.got) }
.dynamic : { *(.dynamic) }
/* We want the small data sections together, so single-instruction offsets
can access them all, and initialized data all before uninitialized, so
we can shorten the on-disk segment size. */
.sdata : { *(.sdata) }
_edata = .;
PROVIDE (edata = .);
__bss_start = .;
.sbss : { *(.sbss) *(.scommon) }
.bss :
{
*(.dynbss)
*(.bss)
*(COMMON)
}
_end = . ;
PROVIDE (end = .);
/* Stabs debugging sections. */
.stab 0 : { *(.stab) }
.stabstr 0 : { *(.stabstr) }
.stab.excl 0 : { *(.stab.excl) }
.stab.exclstr 0 : { *(.stab.exclstr) }
.stab.index 0 : { *(.stab.index) }
.stab.indexstr 0 : { *(.stab.indexstr) }
.comment 0 : { *(.comment) }
/* DWARF debug sections.
Symbols in the DWARF debugging sections are relative to the beginning
of the section so we begin them at 0. */
/* DWARF 1 */
.debug 0 : { *(.debug) }
.line 0 : { *(.line) }
/* GNU DWARF 1 extensions */
.debug_srcinfo 0 : { *(.debug_srcinfo) }
.debug_sfnames 0 : { *(.debug_sfnames) }
/* DWARF 1.1 and DWARF 2 */
.debug_aranges 0 : { *(.debug_aranges) }
.debug_pubnames 0 : { *(.debug_pubnames) }
/* DWARF 2 */
.debug_info 0 : { *(.debug_info) }
.debug_abbrev 0 : { *(.debug_abbrev) }
.debug_line 0 : { *(.debug_line) }
.debug_frame 0 : { *(.debug_frame) }
.debug_str 0 : { *(.debug_str) }
.debug_loc 0 : { *(.debug_loc) }
.debug_macinfo 0 : { *(.debug_macinfo) }
/* SGI/MIPS DWARF 2 extensions */
.debug_weaknames 0 : { *(.debug_weaknames) }
.debug_funcnames 0 : { *(.debug_funcnames) }
.debug_typenames 0 : { *(.debug_typenames) }
.debug_varnames 0 : { *(.debug_varnames) }
/* Top of RAM is 0x48100000, but Cygmon uses the top 4K for its stack. */
.stack 0x480ff000 : { _stack = .; *(.stack) }
/* These must appear regardless of . */
}
Debugger
features for MN10300
The following
documentation describes MN10300-specific features of the GNUPro debugger,
GDB.
For the available
generic debugger options, see Debugging
with GDB in GNUPro Debugging Tools. There are no
MN10300-specific debugger command-line options.
There are two
ways for GDB to talk to an MN10300 target. Each target requires that the
program be compiled with atarget specific linker script.
-
Simulator
GDBs built-in software simulation of the MN10300 processor
allows the debugging of programs compiled for the MN10300 without requiring
any access to actual hardware. For this target the sim.ld linker
script must be specified at compilation. To activate this mode in GDB,
use the target sim command. Then, load the code into the simulator
using the load command and debug it in the normal fashion.
-
Remote target board
For any given target, the eval.ld linker script
must be specified at compilation. To connect to the target board in GDB,
use the target remote <devicename> command,
where <devicename> will be a serial device such as /dev/ttya
(Unix) or com2 (Windows NT). Then, load the code onto the target
board by using the load command. After being downloaded, the program
executes.
When using
a remote target, GDB does not accept the run command. However,
since downloading the program has the side effect of setting the PC to
the start address, you can start your program by using the continue
command.
Simulator
information for MN10300
The simulator
supports the following registers for the MN10300.
-
Volatile registers are d0,
d1,
a0,
a1.
-
Saved registers are d2,
d3,
a2,
a3.
-
Special purpose registers are
sp,
pc,
ccr,
mdr, lar,
lir.
Memory is 256k
bytes starting at location, 0. The stack starts at the highest memory address
and works downward. The heap starts at the lowest address after the text,
data and bss.
There are no
MN10300-specific simulator command-line options.
Configuring,
building and loading CygMon for MN10300
The following
documentation explains how to configure, build, and use the CygMon ROM
monitor program under the Unix operating system.
Configuring
CygMon for MN10300
The following
conventions have been used in in the example configuration.
-
The Unix forward slash is the directory delimiter in all
path descriptions.
-
% is the Unix command
prompt.
-
source_dir represents the complete path
to the directory, which contains the source code. The user can install
the source code in any directory.
-
build_dir
represents the complete path to the user created build directory.
The following
steps show how to configure, build, and load CygMon ROM monitor program
under the Unix operating system.
1.
Create a
build directory and use the cd command to get to that directory.
% cd build_dir
2.
Configure
the toolchain normally.
% source_dir/configure ---target=mn10300-elf
3.
Now
use the following command to build a CygMON image in S-records that can
be downloaded to a PROM burner or emulator.
% make all-target-cygmon
The
S-record image will be in the following file.
build_dir/mn10300-elf/cygmon/mn10300/cygmon.sre
CygMon uses serial port 2 (connector CN2)
on the MN10300 evaluation board. The default settings are 38400,
n,
8, 1.
Building
user programs for MN10300 to run under CygMon
There is a special
linker script for use with CygMON for MN10300.
An example of
the final link command follows.
% mn10300-elf-gcc hello.o -Teval.ld -o hello
eval.ld
is the linker script. The user program is given a program memory area starting
at the 0x48008000 address, and a stack growing down from the 0x480ff000
address.
Space between the program memory and the stack pointer is used for the
heap.
The linker
script should be specified after all other object files and libraries (the
simplest way to ensure this is to place it at the very end of the commandline).
CygMon
(Cygnus ROM monitor) for the MN10200 and MN10300 processors
CygMon is a
ROM monitor designed to be portable across a large number of embedded systems.
It is also completely compatible with existing GDB protocols, thus allowing
the use of a standard ROM monitor with existing GNU tools across a wide
range of embedded platforms.
CygMon has basic
program handling and debugging commands, programs can be loaded into memory
and run, and the contents of memory can be viewed. There are several more
advanced options that can be included at compile time, such as a disassembler
(This of course increases the code size significantly).
Since CygMon
contains a GDB remote stub, full debugging can be done from a host running
GDB to a target running CygMon. Switching between CygMon monitor mode and
GDB stub mode is designed to be transparent to the user, since CygMon can
detect when GDB is communicating with the target and switch into stub mode.
When GDB stops communicating with the target normally, it sends a termination
packet which lets the stub know when to switch to the CygMon monitor mode.
The command
parser was written specifically for CygMon, to provide necessary functionality
in limited space. All commands consist of words followed by arguments separated
by spaces. Abbreviations of command names may be used. Any unique subset
of a command name is recognized as being that command, so du is
recognized to be the dump command. The user is prompted to resolve
any ambiguities. Generally, a command with some or all of its arguments
empty will either assume a default set of arguments or return the status
of the operation controlled by the command.
CygMon includes
an API, which allows user programs, running under it, to use system calls
for various functions. The available system calls allow access to the serial
ports and on-board timer functions, if they are available.
CygMon command list
The following
documentation describes usage of all the commands that can be typed at
the CygMon command prompt. Arguments in [brackets] are optional; arguments
without brackets are required.
Note:
All commands
can be invoked by typing enough of the command name to uniquely specify
the command. Some commands have aliases, which are one letter abbreviations
for commands which do not have unique first letters. Aliases for all commands
are shown in the help screens.
baud
The baud
command sets the speed of the active serial port. It takes one argument,
which specifies the speed to which the port will be set.
Sets the speed
of the active port to 9600 baud.
break
The break
command displays and sets breakpoints in memory. It takes zero or one argument.
With zero arguments, it displays a list of all currently set breakpoints.
With one argument it sets a new breakpoint at the specified location.
Sets a breakpoint
at the 4ff5 address.
disassemble
Usage: disassemble
[location]
The disassemble
command disassembles the contents of memory. Because of the way breakpoints
are handled, all instructions are shown and breakpoints are not visible
in the disassembled code. The disassemble command takes zero or one argument.
When called with zero arguments, it starts disassembling from the current
(user program) pc. When called with a location, it starts disassembling
from the specified location. When called after a previous call and with
no arguments, it disassembles the next area of memory after the one previously
disassembled.
Example: disassemble
45667000
Displays disassembled
code starting at the 45667000 location.
dump
The dump
command shows a region of 16 bytes around the specified location, aligned
to 16 bytes. Thus, dump 65 would show all bytes from 60
through 6f.
Displays 16
bytes starting with 44f0 and ending with 44ff.
go
The go
command starts user program execution. It can take zero or one argument.
If no argument is provided, go starts execution at the current
pc.
If an argument is specified, go sets the pc to that location,
and then starts execution at that location.
Sets the pc
to 40020000, and starts program execution.
help
The help
command without arguments shows a list of all available commands with a
short description of each one. With a command name as an argument, it shows
usage for the command and a paragraph describing the command. Usage is
shown as command name followed by names of extensions or arguments.
Arguments in
[brackets] are optional, plain text arguments are required. Note
that all commands can be invoked by typing enough of the command name to
uniquely specify the command. Some commands have aliases, which are one
letter abbreviations for commands which do not have unique first letters.
Aliases for all commands are shown in the help screen, which displays commands
in the following format.
command
name: (alias, if any) description
of command
Example: help
foo
Shows the help
screen for the command, foo.
load
The load
command switches the monitor into a state where it takes all input as S-records
and stores them in memory. The monitor exits this mode when a termination
record is hit, or certain errors (such as an invalid S-record) cause the
load to fail.
memory
Usage: memory[.size]
location[value]
The memory
command is used to view and modify single locations in memory. It can take
a size extension, which follows the command name or partial command name
without a space, and is a period followed by the number of bits to be viewed
or modified. Options are 8, 16, 32, and 64. Without a size extension, the
memory
command defaults to displaying or changing 8 bits at a time.
The memory
command can take one or two arguments, independent of whether a size extension
is specified. With one argument, it displays the contents of the specified
location. With two arguments, it replaces the contents of the specified
location with the specified value.
Example: memory.8
45f6b2 57
Places the 8 bit
value 57 at the 45f6b2 location.
port
Usage: port
[port number]
The port
command allows control over the serial port being used by the monitor.
It takes zero or one argument. Called with zero arguments it displays the
port currently in use by the monitor. Called with one argument, it switches
the port in use by the monitor to the one specified. It then prints out
a message on the new port to confirm the switch.
Switches the
port in use by the monitor to port 1.
The portcommand
is only usable for the MN10300 processor, not the MN10200 processor.
register
Usage: register
[register name] [value]
The register
command allows the viewing and manipulation of register contents. It can
take zero, one, or two arguments. When called with zero arguments, the
register
command displays the values of all registers. When called with only the
register name argument, it displays the contents of the specified
register. When called with both a register name and a value,
it places that value into the specified register.
Places the 1f
value in the g1 register.
reset
The reset
command resets the board.
step
The step
command causes one instruction of the user program to execute, then returns
control to the monitor. It can take zero or one argument. If no argument
is provided, step executes one instruction at the current pc.
If a location is specified, step executes one instruction at the
specified location.
Executes one
instruction at the current pc.
terminal
The terminal
command sets the type of the current terminal to that specified in the
type
argument. The only available terminal types are vt100 and dumb.
This is used by the line editor to determine how to update the terminal
display.
Sets the type
of the current terminal to a dumb terminal.
transfer
The transfer
or $ function transfers control to the GDB stub. This function
does not actually need to be called by the user, as connecting to the board
with GDB will call it automatically. The transfer command takes
no arguments. The $ command does not wait for a return, but executes
immediately. A telnet setup in line mode will require a return when executed
by the user, as the host computer does not pass any characters to the monitor
until a return is pressed. Disconnecting from the board in GDB automatically
returns control to the monitor.
unbreak
The unbreak
command removes breakpoints from memory. It takes one argument, the location
from which to remove the breakpoint.
Removes a previously
set breakpoint at the 4ff5 memory location.
usage
Shows the amount
of memory being used by the monitor, broken down by category. Despite its
name, it has nothing to do with the usage of any other command.
version
The version
command displays the version of the monitor.
CygMon
API
Currently, the
only APIs that are supported are read and write.
read
int read(int fd, char *ptr, int amt);
Reads amt
bytes of data into ptr from the current serial port. fd
is ignored.
write
int write(int fd, char *ptr, int amt);
Writes amt
bytes of data from ptr to the current serial port. If the
program is running in GDB stub mode, the output will appear in GDB. fd
is ignored.